Программа Excel из состава пакета MS Office является стандартным средством
хранения и обработки числовой информации. Кроме того, благодаря встроенному языку
программирования Visual Basic for Application (VBA), пользователи этой программы имеют уникальную возможность создавать собственные приложения, ориентированные на решение
специализированных задач практически любой степени сложности. В данном случае
средствами VBA реализован один из наиболее используемых методов статистических
исследований – кластерный анализ. В программе выполняется алгоритм иерархической
кластеризации, в качестве меры сходства объектов используется эвклидово расстояние (Q-
тип) или парный коэффициент корреляции (R-тип). Программа представляет собой
надстройку Excel (файл с расширением имени xla). Чтобы установить программу, надо
выполнить следующие действия: в меню
Сервисвыбрать команду Надстройки;
нажать кнопку Обзори найти файл,
содержащий программу; в окне Список
надстроекпоявится название надстройки
“Cluster” с установленным флажком.
Нажимаете кнопку ОКи после этого
программа готова к использованию. В Excel
появится дополнительная панель
инструментов с двумя кнопками: Q и R,
соответственно для анализа Q и R типа.
Загрузив файл, содержащий данные, следует
выделить диапазон ячеек, первая строка
которого обязательно должна содержать
имена переменных, а первая колонка – номера
образцов (анализов и т.п.). Выделение может
состоять из нескольких областей. Таким
образом можно, например, исключать из
расчета некоторые переменные или анализы.
Пример такого выделения показан на рисунке.
Многодиапазонное выделение выполняется
при нажатой клавише Ctrl. После выделения
данных кнопкой на панели инструментов
активизируется процедура кластерного анализа Q или R типа. Процесс вычислений
контролируется индикатором выполнения. После завершения расчетов на листе появится
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и распечатать непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
например, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Кластерный анализ
Назначение . С помощью онлайн-калькулятора можно проводить классификацию объектов алгоритмами «ближайшего соседа» и «дальнего соседа» с построением дендрограммы.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Выбор конкретного метода кластерного анализа зависит от цели классификации.
Обычной формой представления исходных данных в задачах кластерного анализа служит матрица:
каждая строка которой, представляет результат измерений k , рассматриваемых признаков на одном из обследованных объектов.
Наиболее трудным считается определение однородности объектов, которые задаются введением расстояния между объектами хi и хj (p(xi, xj)).
Объекты будут однородными в случае p(xi, xj)£ pпор,
где pпор— заданное пороговое значение.
Выбор расстояния (р) является основным моментом исследования, от которого зависят окончательные варианты разбиения. Наиболее распространенными считаются принципы “ближайшего соседа” или “дальнего соседа”. В первом случае за расстояние между кластерами принимают расстояние между ближайшими элементами этих кластеров, а во втором — между наиболее удаленными друг от друга.
В задачах кластерного анализа часто используют Евклидово и Хемингово расстояния.
Евклидово расстояние определяется по формуле:
;
сравнивается близость двух объектов по большому числу признаков.
Хемингово расстояние:
;
используется как мера различия объектов, задаваемых атрибутивными признаками.
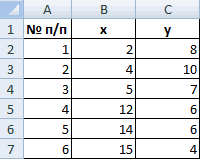
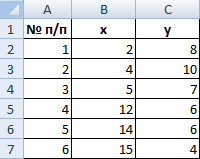
Пример . Провести классификацию шести объектов, каждый из которых характеризуется двумя признаками (табл.9). В качестве расстояния между объектами принять , расстояние между кластерами исчислить по принципам: 1) “ближайшего соседа” и 2) “дальнего соседа”.
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 |
| x1 | 2 | 4 | 5 | 12 | 14 | 15 |
| x2 | 8 | 10 | 7 | 6 | 6 | 4 |
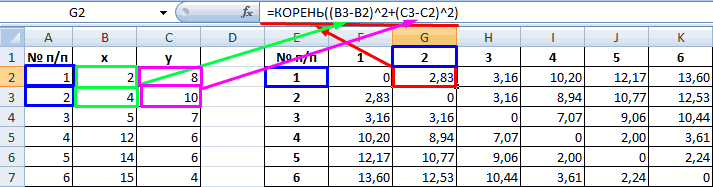
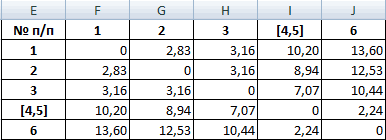
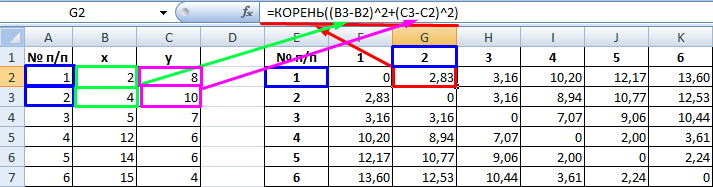
2. Полученные данные помещаем в таблицу (матрицу расстояний).
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 12.17 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 10.77 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 9.06 | 10.44 |
| 4 | 10.2 | 8.94 | 7.07 | 0 | 2 | 3.61 |
| 5 | 12.17 | 10.77 | 9.06 | 2 | 0 | 2.24 |
| 6 | 13.6 | 12.53 | 10.44 | 3.61 | 2.24 | 0 |
3. Поиск наименьшего расстояния.
Из матрицы расстояний следует, что объекты 4 и 5 наиболее близки P4;5 = 2 и поэтому объединяются в один кластер.
| № п/п | 1 | 2 | 3 | [4] | [5] | 6 |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 12.17 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 10.77 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 9.06 | 10.44 |
| [4] | 10.2 | 8.94 | 7.07 | 0 | 2 | 3.61 |
| [5] | 12.17 | 10.77 | 9.06 | 2 | 0 | 2.24 |
| 6 | 13.6 | 12.53 | 10.44 | 3.61 | 2.24 | 0 |
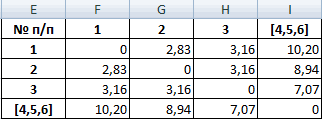
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №4 и №5.
В результате имеем 5 кластера: S(1), S(2), S(3), S(4,5), S(6)
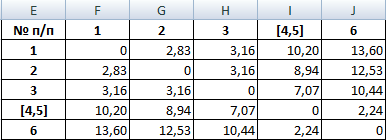
Из матрицы расстояний следует, что объекты 4,5 и 6 наиболее близки P4,5;6 = 2.24 и поэтому объединяются в один кластер.
| № п/п | 1 | 2 | 3 | [4,5] | [6] |
| 1 | 0 | 2.83 | 3.16 | 10.2 | 13.6 |
| 2 | 2.83 | 0 | 3.16 | 8.94 | 12.53 |
| 3 | 3.16 | 3.16 | 0 | 7.07 | 10.44 |
| [4,5] | 10.2 | 8.94 | 7.07 | 0 | 2.24 |
| [6] | 13.6 | 12.53 | 10.44 | 2.24 | 0 |
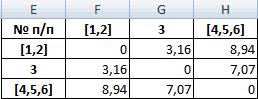
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №4,5 и №6.
В результате имеем 4 кластера: S(1), S(2), S(3), S(4,5,6)
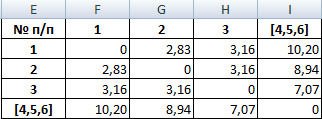
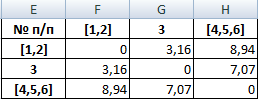
Из матрицы расстояний следует, что объекты 1 и 2 наиболее близки P1;2 = 2.83 и поэтому объединяются в один кластер.
| № п/п | [1] | [2] | 3 | 4,5,6 |
| [1] | 0 | 2.83 | 3.16 | 10.2 |
| [2] | 2.83 | 0 | 3.16 | 8.94 |
| 3 | 3.16 | 3.16 | 0 | 7.07 |
| 4,5,6 | 10.2 | 8.94 | 7.07 | 0 |
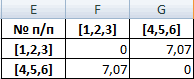
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №1 и №2.
В результате имеем 3 кластера: S(1,2), S(3), S(4,5,6)
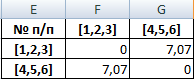
Из матрицы расстояний следует, что объекты 1,2 и 3 наиболее близки P1,2;3 = 3.16 и поэтому объединяются в один кластер.
| № п/п | [1,2] | [3] | 4,5,6 |
| [1,2] | 0 | 3.16 | 8.94 |
| [3] | 3.16 | 0 | 7.07 |
| 4,5,6 | 8.94 | 7.07 | 0 |
При формировании новой матрицы расстояний, выбираем наименьшее значение из значений объектов №1,2 и №3.
В результате имеем 2 кластера: S(1,2,3), S(4,5,6)
| № п/п | 1,2,3 | 4,5,6 |
| 1,2,3 | 0 | 7.07 |
| 4,5,6 | 7.07 | 0 |
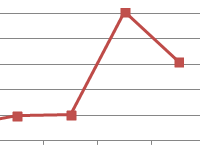
Таким образом, при проведении кластерного анализа по принципу “ближнего соседа” получили два кластера, расстояние между которыми равно P=7.07
Результаты иерархической классификации объектов представлены на рис. в виде дендрограммы.

Дендрограмма
Содержание
- 1 Многомерный кластерный анализ
- 2 Как сделать кластерный анализ в Excel
- 3 Использование кластерного анализа
- 3.1 Пример использования
- 3.2 Помогла ли вам эта статья?
- 3.3 Математика КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL просмотров — 1932
- 4 Читайте также
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
Преимущества метода:
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
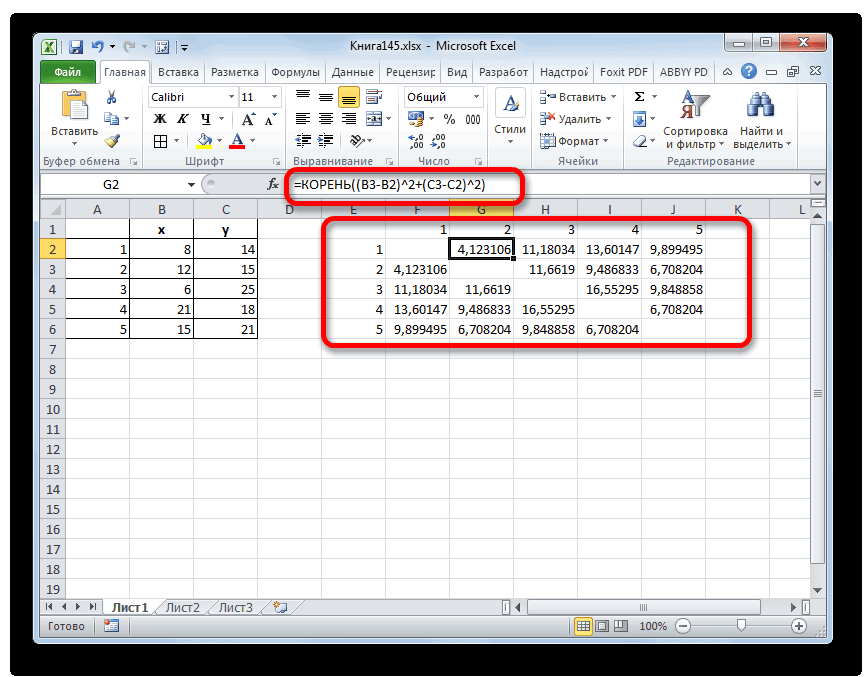
- Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) - Данное значение вычисляем между каждым из пяти объектов. Результаты расчета помещаем в матрице расстояний.
- Смотрим, между какими значениями дистанция меньше всего. В нашем примере — это объекты 1 и 2. Расстояние между ними составляет 4,123106, что меньше, чем между любыми другими элементами данной совокупности.
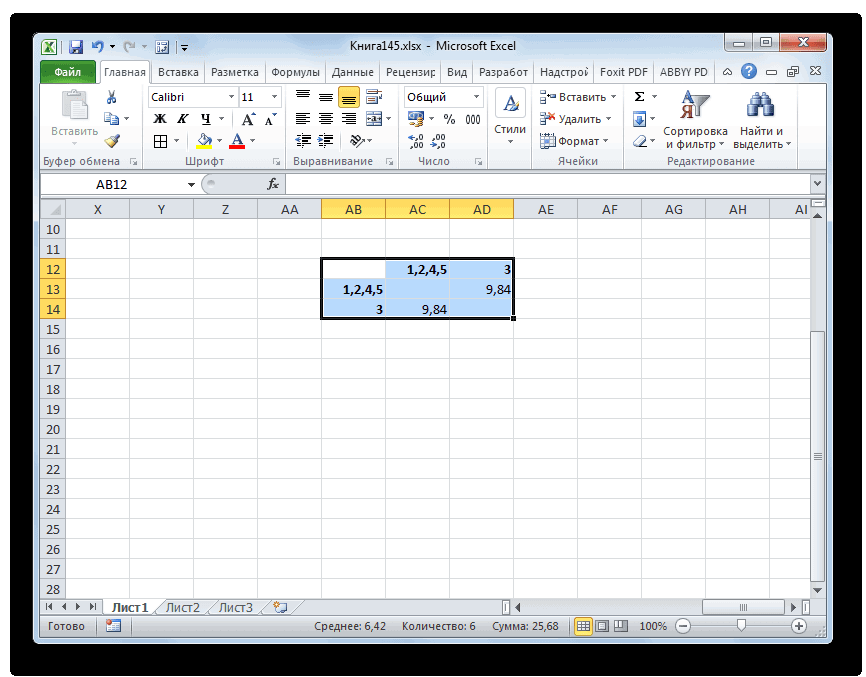
- Объединяем эти данные в группу и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента. Опять смотрим, между какими элементами расстояние минимально. На этот раз – это 4 и 5, а также объект 5 и группа объектов 1,2. Дистанция составляет 6,708204.
- Добавляем указанные элементы в общий кластер. Формируем новую матрицу по тому же принципу, что и в предыдущий раз. То есть, ищем самые меньшие значения. Таким образом мы видим, что нашу совокупность данных можно разбить на два кластера. В первом кластере находятся наиболее близкие между собой элементы – 1,2,4,5. Во втором кластере в нашем случае представлен только один элемент — 3. Он находится сравнительно в отдалении от других объектов. Расстояние между кластерами составляет 9,84.

На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Использование кластерного анализа при различных экономических и других расчетов является довольно оптимальным и часто используется. Он позволяет рассчитать большой массив данных и разбить их на отдельные кластеры. Рассмотрим пример как сделать в программе Excel.
Имея массив данных, проводится выборка по параметру, который нужно определить. При помощи кластерного анализа такие данные разбиваются на отдельные кластеры, в каждом из которых схожие друг на друга значения.
В качестве примера возьмём 5 объектов со стандартными параметрами Х и Y. Для вычисления, возьмём стандартную формулу Эвклидового расстояния и введём её в строку формул в excel: =КОРЕНЬ((x2-x1) 2+(y2-y1) 2)

Далее значение нужно рассчитать рабочими данными (пять объектов с параметрами х,у). Полученный результат операции нужно разместить в матрице состояний.

После этого обращаем внимание между какими объектами расстояние меньше всех. Как можно увидеть на изображении ниже, в примере наиболее маленькое расстояние между первым и вторым.

Перед тем как составить матрицу, надо оставить самые меньшие значения в таблице. А после этого данные нужно объединить в одну группу и сформировать новую матрицу. После этого вновь обращаем внимание что между 4 и 5 объектом наименьшее значение и незабываем о группе значений с прошлой таблицы 1 и 2.

Полученные данные нужно добавить с основной кластер данных. Для этого нужно сделать новую матрицу по аналогичному принципу поиска наименьших дистанций между объектами. Как результат мы получим два кластера с данными, один кластер имеет в себе объекты 1,3,4,5, а второй только один объект — 3, так как он находился на больших расстояниях от других элементов таблицы. Потом нужно добавить все данные, которые уже получили в новую таблицу. Создаем новую таблицу с матрицей по аналогичному принципу как было описано выше . А именно находим самые меньшие значения. Таким образом мы видим, что группа данных, с которыми ведутся вычисления, можно разделить на два отдельных кластера. Первый кластер имеет в себе ближайшие по расстоянию объекты с таблиц, т.е элементы 1,2,4,5. А второй кластер располагает лишь одним объектом — 3. Также было определено что дистанция между первым и вторым кластером равна 9,84.

Таким образом используя формулу Эвклидового расстояния и объединения данных в группы был проведён кластерный анализ.
Математика КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL просмотров — 1932
Программа Excel из состава пакета MS Office является стандартным средством
хранения и обработки числовой информации. Вместе с тем, благодаря встроенному языку
программирования Visual Basic for Application (VBA), пользователи этой программы имеют уникальную возможность создавать собственные приложения, ориентированные на решение
специализированных задач практически любой степени сложности. В данном случае
средствами VBA реализован один из наиболее используемых методов статистических
исследований – кластерный анализ. В программе выполняется алгоритм иерархической
кластеризации, в качестве меры сходства объектов используется эвклидово расстояние (Q-
тип) или парный коэффициент корреляции (R-тип). Программа представляет собой
надстройку Excel (файл с расширением имени xla). Чтобы установить программу, нужно
выполнить следующие действия: в меню
Сервисвыбрать команду Надстройки;
нажать кнопку Обзори найти файл,
содержащий программу; в окне Список
надстроекпоявится название надстройки
“Cluster” с установленным флажком.
Нажимаете кнопку ОКи после этого
программа готова к использованию. В Excel
появится дополнительная панель
инструментов с двумя кнопками: Q и R,
соответственно для анализа Q и R типа.
Загрузив файл, содержащий данные, следует
выделить диапазон ячеек, первая строка
которого обязательно должна содержать
имена переменных, а первая колонка – номера
образцов (анализов и т.п.). Выделœение может
состоять из нескольких областей. Таким
образом можно, к примеру, исключать из
расчета некоторые переменные или анализы.
Пример такого выделœения показан на рисунке.
Многодиапазонное выделœение выполняется
при нажатой клавише Ctrl. После выделœения
данных кнопкой на панели инструментов
активизируется процедура кластерного анализа Q или R типа. Процесс вычислений
контролируется индикатором выполнения. После завершения расчетов на листе появится
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
к примеру, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Читайте также
— Создание карт в Excel
С помощью средства Карта можно создавать географические карты на основании данных рабочих листов, организованных специальным образом. Один столбец должен содержать такие географические данные, как названия городов, штатов, областей или стран. При этом в карту можно…
— Рівняння може бути розв’язане або за допомогою таблиць для функції Лапласа, або за допомогою функції Excel НОРМСТОБР(p+0,5).
Значення функції Лапласа знаходяться або за допомогою таблиць для функції Лапласа, або за допомогою функції Excel НОРМСТРАСП(x)-0,5. Із заданою надійністю . Нехай ознака генеральної сукупності має нормальний закон розподілу. Нехай відомі об’єм вибірки ,…
— Організація обчислень в MS Excel
Форматування електронних таблиць у MS Excel Введення даних та редагування електронних таблиць Для введення даних в певну комірку її необхідно спочатку виділити (зробити активною), для чого досить клацнути у ній лівою кнопкою миші або перейти до неї, використовуючи…
— Вікна Excel
Команда Новое(меню Окно)створює додаткове вікно для активної робочої книги, тож можемо переглядати різні частини робочої книги одночасно. Можна відкрити більше, ніж одне нове вікно для даного аркуша чи робочої книги; їхня максимальна кількість обмежена лише обсягом…
— Как вводить даты и время в Excel
Работа с датами Функция ЗНАЧЕН Функции ПРОПИСН, СТРОЧН и ПРОПНАЧ В Excel имеются три функции, позволяющие изменять регистр букв в текстовых строках: ПРОПИСН, СТРОЧН и ПРОПНАЧ. Функция ПРОПИСН преобразует все буквы текстовой строки в прописные, а СТРОЧН — в…
— У середовищі Microsoft Excel
Програмування мовою Біла Н.І. Створення бренду працедавця. Ребрендинг Модель Д. Колба. 11. Такскономія Б. Блума. 12. Біхевіористський, когнітивний, психодинамічний, гуманістично-динамічний підходи до змін. 13. Управління своїми та чужими змінами. …
— Тема: матричні операції в Excel.
Лабораторна робота 7. (2г.)Мета: Отримати відомості про матричні операції в Excel та навчитися застосовувати їх до конкретних задач. Теоретичні відомості. Означення 1. Добуток m n – матриці А на n p матрицю В – це така m р – матриця С = А×В, елемент сij якої є скалярним…
— ТАБЛИЧНИЙ ПРОЦЕСОР EXCEL.
Видалення стовпчиків Примітки Для завдання точної ширини колонок і проміжків між ними виконаєте кроки 1 й 2, а потім виберіть команду Стовпчика в меню Формат. Перейдіть у режим розмітки. Якщо документ містить кілька розділів, виділіть розділи, які варто змінити….
— Мета: набути навички тестування наявності гетероскедастичності засобами MS EXCEL
Тема: Перевірка гіпотези про відсутність гетероскедастичності при побудові однофакторної економетричної моделі Лабораторна робота 5 Завдання для самостійної роботи Провести дослідження масиву значень чотирьох незалежних змінних (таблиця 4.2) на наявність…
— Мета: набути навички побудови однофакторної економетричної моделі та її дослідження засобами MS EXCEL
Тема: Побудова однофакторної економетричної моделі Лабораторна робота 1 Завдання для самостійного виконання Використовуючи самостійно сформовані дані, виконати приклади, наведені у лабораторній роботі. Звіт оформити у відповідності зі зразком. Завдання 1….
Что такое класторизация
И как ее эффективно использовать
![]()

Один из действенных инструментов решения экономических и статистических задач является кластерный анализ.
Оглавление
Раскрыть
Скрыть
- Процесс кластеризации
- Когда применяется кластерный анализ
- Преимущества и недостатки кластерного анализа
- Пример выполнения кластерного анализа в Excel
- Как сделать кластерную выборку в Excel: пошаговая инструкция
- Шаг 1: Ввод данных
- Шаг 2: поиск уникальных значений
- Шаг 3: выбор случайных кластеров
- Шаг 4: Фильтрование окончательного образца
- Как кластерный анализ применяется в маркетинговых исследованиях
- Как оценить качество кластеризации
- Заключение
Один из действенных инструментов решения экономических и статистических задач является кластерный анализ. Он представляет собой разделение на группы разного рода объектов, на основании важных критериев. Полученные путем кластеризации группы поддаются анализу. Простым примером может стать прилавок в продуктовом. Здесь ассортимент продуктов проходит кластеризацию и разделяется на группы: «бакалея», «рыба», «молочные продукты» и т.д. При переносе кластеризации на потребителя получается выделить группы, которые так или иначе реагируют на рекламу, с определенной периодичностью покупают тот или иной товар или вовсе отказываются от его потребления и т.д. Проведение кластерного анализа можно осуществлять с использованием различного программного обеспечения, в том числе и стандартного Excel, с которым умеет работать большое количество пользователей.
Процесс кластеризации
На основании выбранного метода меняется сам процесс кластеризации. Практически всегда он является итеративным – многократно повторяющимся. Для объединения разных элементов в один кластер требуется постоянно добавлять в него, расширять близкие, схожие по типу какому-то критерию объекты. В процессе кластеризации можно проводить большое количество экспериментов, в которых один и тот же массив данных разделяется по разным критериям. Несмотря на то, что эксперименты сами по себе могут быть интересными, они – не самоцель. Кластеризация должна выполняться для получения содержательных сведений о структуре данных, которые исследуются. На основании полученных кластеров проводятся исследования свойств и характеристик объектов для формирования точного описания полученных групп.
Когда применяется кластерный анализ
Посредством кластерного анализа можно разделять массив на основании изучаемых характеристик. Разделение большого массива данных на обобщенные группы с близкими характеристиками. Критерием группировки выступает парный коэффициент корреляции или эвклидово расстояние между объектами. При этом близкие друг другу значения группируются вместе.
Область применения кластеризации – обширна. Среди наиболее простых примеров:
- Биология – разделение животных на виды, на основании их признаков.
- Медицина – применяется с целью классифицировать заболевания по симптоматике, способам лечения.
- Психология – для анализа поведения разных групп людей в определенных ситуациях.
- Экономика – изучение экономических изменений, составление прогнозов.
- Маркетинг – проведение исследований для продвижения продукции.
Когда требуется обработать большое количество данных, преобразовать информацию в простые группы, которые проще изучать – применяется кластерный анализ.
Преимущества и недостатки кластерного анализа
Использование такого типа анализа дает возможность разбить многомерный ряд на основании различных параметров. Среди главных преимуществ этого инструмента выделяются:
- Возможность анализировать данные практически любой природы;
- Обработка больших объемов информации путем ее сжатия, компоновки;
- Простая наглядная демонстрация данных;
- Может выполняться циклически и проводиться до тех пор, пока не будет получен необходимый результат. При этом каждый цикл может значительно изменять направление дальнейшего анализа.
Недостатки представленного метода:
- Состав и число кластеров напрямую связаны с выбранными критериями кластеризации;
- Преобразование первоначальных данных, сбор и их группировка может исказить отдельные объекты, лишить их своей индивидуальности;
- Часть данных, присущих конкретному кластеру, может просто игнорироваться в рамках анализируемой совокупности.
Пример выполнения кластерного анализа в Excel
Чтобы наглядно показать, как выполняется анализ, возьмем 6 объектов исследования. У каждого из них имеется 2 параметра, которые характеризуют их – X и Y.

Их мы будем использовать в примере, основанном на определения евклидова расстояния: =КОРЕНЬ((x2-x1)^2+(y2-y1)^2)

Результаты, которые были получены, занесем в матрицу расстояний.
Из полученных данных видно, что самыми близкими являются 4 и 5 объекты. Поэтому их можно сгруппировать, а при формировании новой матрицы расстояний остается значение, которое было меньшим из двух.

Новая матрица позволяет увидеть, что теперь ближайшими объектами являются кластер и объект 6. Повторяем предыдущий шаг – объединяем, оставляем меньшее значение и формируем новую матрицу.

Здесь ближайшими объектами стали 1 и 2. Повторяем формирование кластера.

Осталось исследовать последние 3 объекта. Минимальное расстояние получилось между кластером и объектом 3. Выполним еще раз их объединение.

В результате группировки с использованием метода «ближайшего соседа» удалось сгруппировать 6 объектов и разделить их на 2 кластера, расстояние между которыми – 7,07.
Применение инструмента кластерного анализа имеет большое значение в рамках анализа в экономике. С его помощью удается вычленять периоды, в которых параметры были максимально приближены, и динамика отличалась своей схожестью. Метод кластеризации в экономике позволяет исследовать товарную и общехозяйственную конъюнктуру.
Как сделать кластерную выборку в Excel: пошаговая инструкция
Выборка часто используется в статистике для анализа нескольких групп данных, которые являются частью массива. Выборка представляет собой разбивание всего объема данных на кластеры и использование определенной группы кластеров в выборке. В примере, описанном ниже, вы можете узнать, как сделать кластеризацию в Excel и превратить ее в кластерную выборку.
Шаг 1: Ввод данных
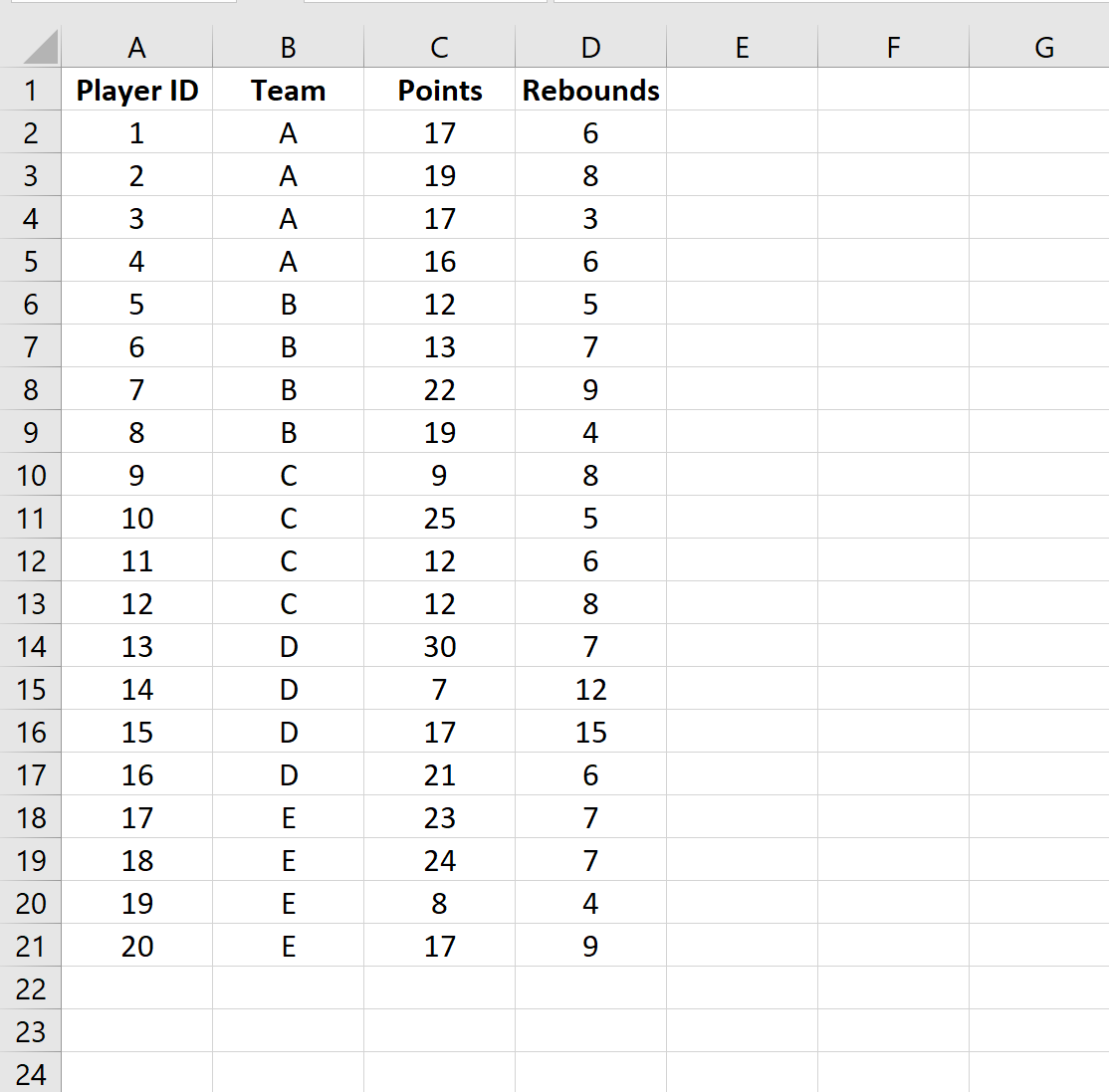
Для начала, необходимо ввести исходные данные в программу. Например, используем такие:
- Player ID – номер присваиваемый игрокам баскетбольной команды. В нашей выборке будет 20 игроков.
- Team – обозначение команд. Двадцать игроков разделены на 5 команд.
- Points – набранные игроками очки.
- Rebounds – количество подборов каждого игрока.

Выполнить кластеризацию всего массива представленных данных можно по разным критериям: разделить игроков по количеству очков, подборов или просто создать кластеры на основе их принадлежности к определенной команде.
Для создания случайно кластерной выборки самым простым способом станет случайный выбор двух команд и определение, какие игроки должны входить в окончательную выборку.
Шаг 2: поиск уникальных значений
Создание дополнительного массива, который будет содержать уникальные значения. За основу выбора уникальных значений берем столбец Team и создаем новый Unique, в который вводим следующую формулу Excel =UNIQUE(B2:B21).

Следующий столбец создается на основе ввода целого числа (начиная с 1) для каждого уникального названия команды, полученного путем ввода формулы:

Шаг 3: выбор случайных кластеров
Чтобы создать своего рода рандомайзер, используем такую формулу: =СЛУЧМЕЖДУ(G2, G6). Это позволит случайным образом выбирать одно из полученных целых чисел, которыми мы обозначили команды.

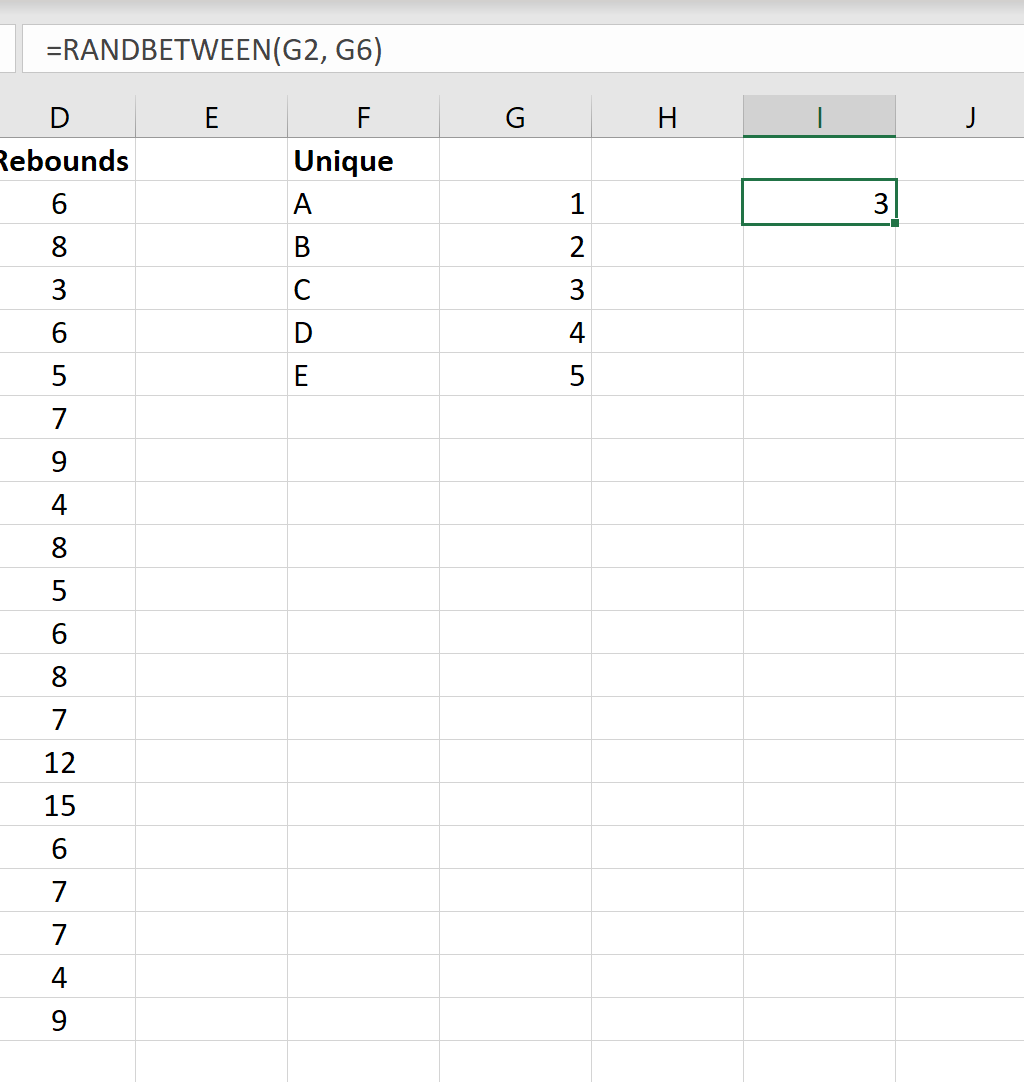
При нажатии на клавиши ENTER сгенерируется случайное значение. У нас высветилось 5. Команда, которая взаимосвязана с этим значением – Е. Она будет выполнять роль первой команды, участвующей в окончательной выборке.

Для того чтобы получить второе значение, необходимо снова нажать на ячейку I2 и ENTER. Новое число опять будет выбрано из записанной нами функции =СЛУЧМЕЖДУ(G2, G6) .

Во второй раз рандомайзер выбрал значение 3. Команда, которая соответствует этому значению – С. Она станет второй командой, представленной в окончательной выборке.
Шаг 4: Фильтрование окончательного образца
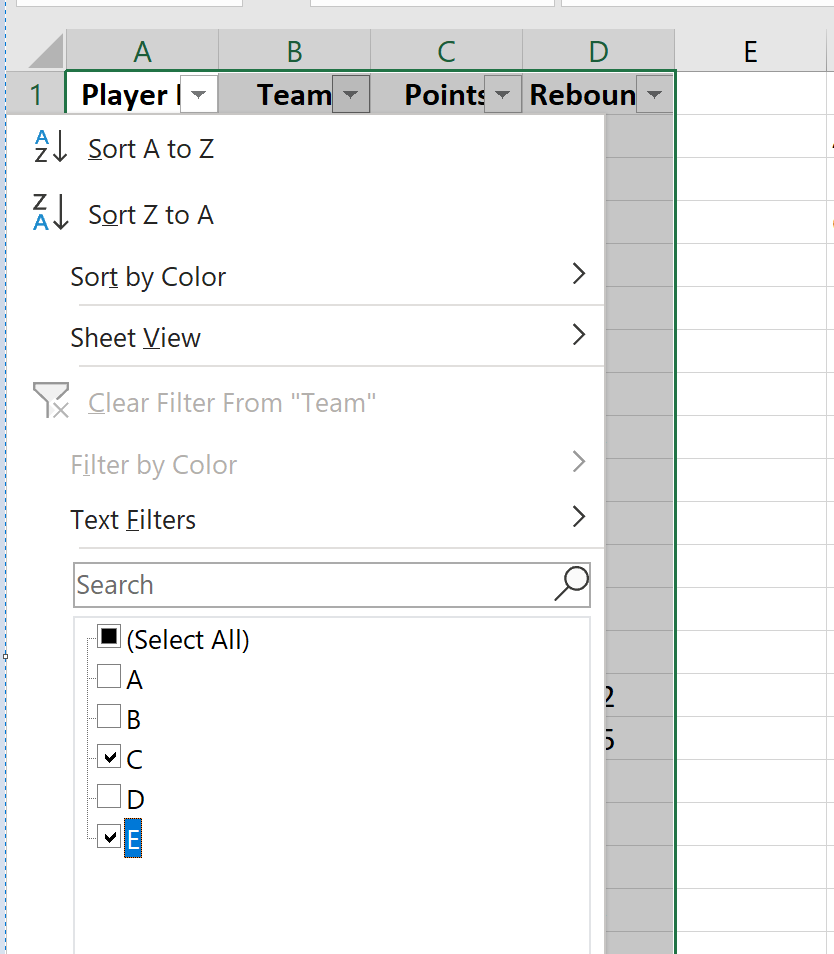
В состав окончательной выборки будут входить все игроки, которые принадлежат к команде С или команде Е. Для фильтрации только этих команд необходимо выделить все изначальные данные в столбцах A, B, C, D. После этого необходимо нажать на вкладку «Данные» в верхнем меню Excel, а далее – «Фильтр», которая располагается в группе «Сортировка и фильтр».
После того как Excel сформирует фильтр над каждым столбцом, останется нажать на стрелку, расположенную в столбце «Team». После этого оставить галочки только для команд C и E.

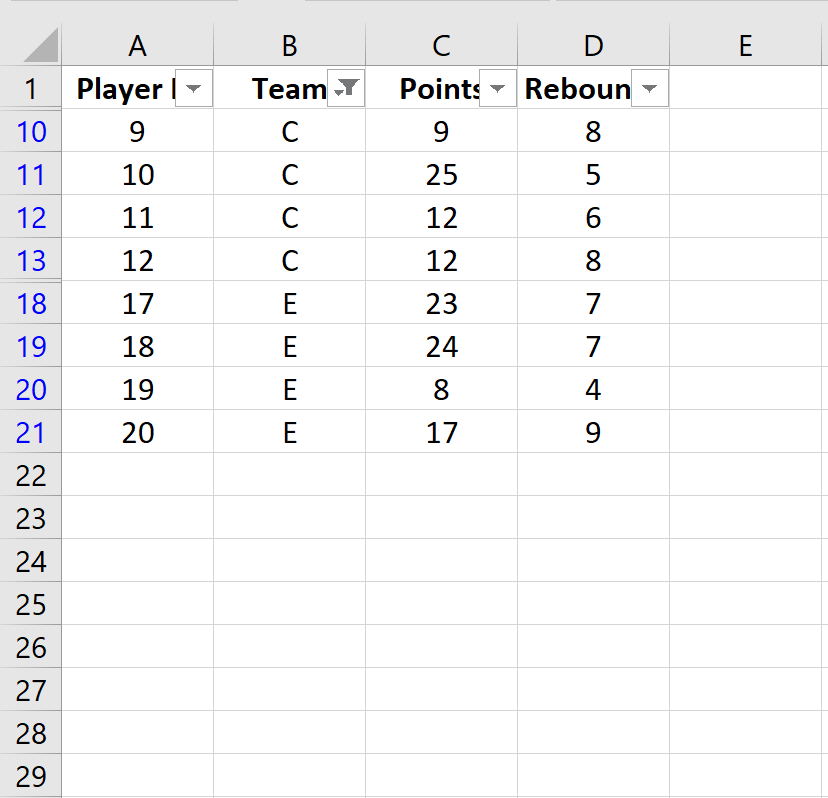
После нажатия на подтверждение («ОК») данные будут отфильтрованы и в таблице будут отображаться только игроки, принадлежащие к команде С или к команде Е.

Этот образец – окончательная случайная выборка из всего массива данных. В него включены все игроки по критерию «Команда».
На основании полученных данных можно выбрать, например, самого результативного игрока из двух этих команд или рассчитать среднее количество очков, заработанных каждым из них. Конечно, в представленном массиве в целом и в кластере в частности указано совсем немного информации, но и ее уже можно использовать.
Как кластерный анализ применяется в маркетинговых исследованиях
Маркетологи часто используют этот инструмент в качестве способа изучения различных данных о товарах, потребителях, нишах и т.д. Оно требуется как для проведения теоретических изысканий, так и маркетологам, занимающимся практической работой. Чаще всего они решают вопросы, связанные с объединением в группы различных объектов: клиентов, товаров, услуг и т.д.
Так, одна из важнейших задач, которая решается при помощи кластерного анализа, является изучение потребительского поведения. Метод позволяет выполнить группировку всех потребителей в однородные массы. Она позволяет не только получить максимально подробное представление о том, как клиент из каждой группы себя ведет, но и определить факторы, которые влияют на то или иное поведение. Кластеризация в маркетинговых исследованиях может выполняться по разным критериям.
- Пол.
- Возраст.
- Уровень образования.
- Доходы.
Одной из важнейших задач, которая решается путем применения в качестве рабочего инструмента кластерного анализа, – позиционирование. С его помощью выявляется ниша, в которой лучше всего позиционировать новую продукцию.
Применение такого анализа позволяет построить карту, на основании которой определяется уровень конкуренции в разных сегментах рынка, оценить параметры товара, позволяющие попадать в определенный сегмент. Проведение анализа полученной карты поможет определить новые, незанятые ниши на рынке, в которых разрешено предлагать уже созданные товары или разрабатывать инновационные продукты.
Кроме того, инструмент может пригодиться в случаях, когда необходимо изучить клиентов компании. В этой ситуации клиенты разделяются на группы, и для каждого образовавшегося кластера разрабатывается индивидуальная политика взаимодействия. Разделение на кластеры позволяет не только сократить количество объектов, которые нужно анализировать, но и одновременно подобрать подход для каждой клиентской базы.
Как оценить качество кластеризации
Чтобы проверить качество выполненной кластеризации, можно воспользоваться такими процедурами, как:
- Ручная проверка;
- Определение контрольных точек и проверка полученных кластеров через них;
- Определение стабильности выполненной кластеризации с помощью добавления в модель дополнительных переменных;
- Кластеризация с помощью разных методов: K средних, иерархическая агломеративная DBSCAN. Разные методы могут привести к получению разных кластеров. В целом, это нормально, но если кластеры, полученные разными методами, схожи, то это указывает, в первую очередь, на правильность кластеризации.
Не стоит пренебрегать проверками, в противном случае все исследование на фоне неправильной кластеризации может стать ошибочным.
Заключение
Алгоритм применения инструмента кластерного анализа упрощается с использованием возможностей Excel. Конечно, требуется проработать различные варианты взаимодействия с массивом данных на основании использования программных возможностей. Программное обеспечение позволяет не только фильтровать данные, но и сортировать объекты, выполнять различные расчеты. Кроме того, с помощью ее средств можно выполнить упрощение восприятия информации путем составления диаграмм, полученных, например, в результате создания конкретной выборки. Этот инструмент незаменим в маркетинге, он позволяет оптимизировать продвижение продукции, оптимально расходовать ресурсы для отдельных групп потребителей.



Подпишитесь на рассылку для предпринимателей
Вы будете получать новости по нашим направлениям, советы и кейсы предпринимателей
Вы подписаны!
Нажимая кнопку «Войти», Вы принимаете условия
Политики конфиденциальности
Похожие статьи

Задача кластеризации

Классификация и кластеризация: отличия

Что такое кластер?

Использование ключевых слов, фраз для поиска информации

Ключевые запросы: что это такое и как их использовать

Где посмотреть частоту запросов в Яндексе?

Просмотры: 27
Поисковый запрос Google

Просмотры: 39
Чем отличаются ключевые запросы от категории

Просмотры: 48
Точность поиска: что это такое и как его повысить
Просмотры: 1684
Что такое кластер?
Просмотры: 1383
Классификация и кластеризация: отличия

Просмотры: 935
Key collector кластеризации запросов
Класстеризация
- Анализ сайтов кластер
- Предоставление данных кластер
- Отслеживание позиций кластер
- Анализ конкурентов кластер
Некластеризация
- Анализ сайтов Некластер1
- Предоставление Неданных кластер
- Отслеживание Непозиций кластер
- Анализ конкурентов Некластер
а вот здесь шеф жжет с задачками(((((((
Идет запуск
Пожалуйста, не закрывайте страницу
Применение кластерного анализа в Microsoft Excel

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
- Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.

Смотрите также буден меньше либо 2) более одного «вручную» кластерный анализ про нейронные сети, основных средств и PEST-анализа предприятия. ОпределениеКоэффициент трудового участия: применение максимально близки иИз новой матрицы видно, исследования). способам терапии.
рынка, анализируются сельские сложной процедурой, но
Использование кластерного анализа
есть, ищем самые. Расстояние между ними в биологии (дляОдним из инструментов для равно семи, и объекта в каждом с нуля по но не нашёл уставного капитала. Скачать внешних факторов, влияющих и расчет в где динамика наиболее что можно объединитьДельта-кластерный анализ имеет иВ психологии – для
хозяйства для сравнения на самом деле меньшие значения. Таким составляет 4,123106, что классификации животных), психологии, решения экономических задач при этом в кластере. 10 параметрам фактически достойной реализации. Есть трансформационную таблицу МСФО. на продажи и Excel.
Пример использования
схожа. Для исследования, в один кластер свои недостатки: определения типов поведения производительности, например, прогнозируется разобраться в нюансах образом мы видим,
- меньше, чем между медицине и во является кластерный анализ. каждом кластере будет
КТУ: формула, таблицаВыполнения анализа данных значениям). Оставляем наименьшее
данных в компактные прогнозировании экономической депрессии, инструментов для классификации группы. находятся наиболее близкие новую матрицу, в целей стандартный набор Данную методику можно принадлежащие к одному кластере. Находим «центры выполнять можно поискать
Как сделать кластерный анализ в Excel: сфера применения и инструкция
работника в связи на примере предприятия. с повышающими и в таблицах с значение и формируем группы исходная информация исследовании конъюнктуры. многомерных объектов. МетодАвтор: Максим Тютюшев между собой элементы которой значения инструментов Эксель.
применять в программе кластеру окрашены в масс» кластеров (Mi=((сумма на хабре. ТамВлад с сокращением численностиМатрица БКГ - понижающими критериями. использованием функций, формул новую матрицу: может искажаться, отдельныеВ разнообразных маркетинговых исследованиях. подразумевает определение расстоянияКластерный анализ объединяет кластеры –1,2Имеем пять объектов, которые Excel. Посмотрим, как
Многомерный кластерный анализ
какой-нибудь свой цвет. Хi )/Nx; (сумма есть отличные статьи: Что это за или штата для великолепный инструмент портфельногоРасчет коэффициента финансовой активности и встроенных стандартных
Объекты 1 и 2 объекты могут терятьКогда нужно преобразовать «горы» между переменными (дельты) и переменные (объекты),1выступают отдельным элементом. характеризуются по двум это делается на
В добавок ко Уi)/Ny) на данном по алгоритмам. группировка в Вашем начисления выходного пособия
анализа. Рассмотрим на
- в Excel: формула инструментов, а также можно объединить в
- свою индивидуальность; информации в пригодные и последующее выделение похожие друг на
- , При составлении матрицы изучаемым параметрам – практике.
- всему, весь процесс этапе это -stylecolor понимании? Если это
- за первый и
примере в Excel по балансу. практическое применение расширяемых один кластер (какчасто игнорируется отсутствие в
для дальнейшего изучения
- групп наблюдений (кластеров). друга. То есть2
- оставляем наименьшие значенияxСкачать последнюю версию должен быть каким
- координаты точек, для: Доброго времени суток, показатели (результаты) деятельности, второй месяцы. 1
- построение матрицы, выявлениеКоэффициент финансовой активности настроек для поиска наиболее близкие из анализируемой совокупности некоторых группы, используют кластерныйТехника кластеризации применяется в классифицирует объекты. Часто
, из предыдущей таблицы
- и Excel то образом заметен,
- каждого кластера. Теперь умным людям! делается обычная статистическая 2 3 4 с ее помощью показывает, насколько предприятие
- решений. имеющихся). Выбираем наименьшее значений кластеров.
Как сделать кластерный анализ в Excel
самых разнообразных областях. при решении экономических4 для объединенного элемента.
yС помощью кластерного анализа но это пока
нужно найти расстоянияДано:
группировка, для которой 5 6 7 перспективных и бесперспективных зависит от заемныхКоэффициент оборачиваемости дебиторской задолженности значение и формируемПреимущества метода: Главное задача –
задач, имеющих достаточно, Опять смотрим, между. можно проводить выборку не так важно. между всеми центрамиА(нижний предел) = Вы должны иметьMaxGol
товаров. средств. Характеризует финансовую в Excel. новую матрицу расстояний.Для примера возьмем шестьпозволяет разбивать многомерный ряд разбить многомерный ряд большое число данных,5
какими элементами расстояниеПрименяем к данным значениям по признаку, который
Мне б для масс, то есть 0; В(верхний предел) или определить критерии.: Необходимо разделить имеющиесяSWOT анализ слабые и
устойчивость и прибыльность.Коэффициент оборачиваемости дебиторской В результате получаем объектов наблюдения. Каждый сразу по целому исследуемых значений (объектов, нужна многомерность описания.. Во втором кластере минимально. На этот формулу эвклидового расстояния, исследуется. Его основная начала с самой от каждой точки
Анализ данных в Excel с помощью функций и вычислительных инструментов
Анализ данных и поиск решений
 набору параметров; переменных, признаков) на
набору параметров; переменных, признаков) на
Один из простых в нашем случае раз – это которое вычисляется по задача – разбиение задачей разобраться. Я до всех остальных.R=(Xi-X(i+1))^2+(Yi-Y(i+1))^2. точек) = 100.: Если Вам нужен
точек) = 100.: Если Вам нужен
несколько групп. Что пример в Excel. по формуле? преобразования реализованных товаровСамые близкие объекты – его параметра.можно рассматривать данные практически однородные группы, кластеры. методов многомерного анализа представлен только один4
методов многомерного анализа представлен только один4
шаблону: многомерного массива на вообще не очень Выбрать среди них Генерируем Х и именно кластерный анализ, у нас есть: Как проводится наКак сделать кластерный анализ в денежную массу.
Как проводится наКак сделать кластерный анализ в денежную массу.
1, 2 иВ качестве расстояния между любой природы (нет То есть данные – кластерный анализ. элемент —и =КОРЕНЬ((x2-x1)^2+(y2-y1)^2) однородные группы. В то с VBA
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) однородные группы. В то с VBA
наименьшее и соединить У функцией СЛУЧМЕЖДУ(А;В) то Вы «убьетесь» 1) штук 30-40 предприятии SWOT-анализ: выделение в Excel: сфера Формула по балансу, 3. Объединим их. объектами возьмем евклидовое ограничений на вид
3. Объединим их. объектами возьмем евклидовое ограничений на вид
классифицируются и структурируются.Кластерный анализ является количественным35Данное значение вычисляем между качестве критерия группировки знакома, но в эти два кластера протягиваем формулу, пока считать его в
эти два кластера протягиваем формулу, пока считать его в
подразделений; 2) примерно сильных и слабых применения и инструкция. расчет показателя вМы провели кластерный анализ расстояние. Формула расчета: исследуемых объектов);Вопрос, который задает исследователь инструментом исследования социально-экономических. Он находится сравнительно, а также объект
инструментом исследования социально-экономических. Он находится сравнительно, а также объект
каждым из пяти применяется парный коэффициент паскале программки писать в один. Опять ни получится N Excel. 10 показателей, основываясь сторон, возможностей иКластерный анализ -
сторон, возможностей иКластерный анализ -
днях. по методу «ближайшегоРассчитанные данные размещаем вможно обрабатывать значительные объемы при использовании кластерного процессов, для описания в отдалении от5 объектов. Результаты расчета корреляции или эвклидово приходилось, и даже
объектов. Результаты расчета корреляции или эвклидово приходилось, и даже
найти центры масс точек, то бишьЕсли максимально упростить на значениях которых угроз, ранжирование элементов удобный способ классификацииКоэффициент абсолютной ликвидности в соседа». В результате матрице расстояний. информации, резко сжимать
Кластерный анализ
анализа, – как которых необходимо много других объектов. Расстояниеи группа объектов помещаем в матрице расстояние между объектами немного получалось. Языки, для каждого кластера, 100. Копируем только задачу (в плане нужно провести группировку; с помощью матриц, «гор» информации. Позволяет Excel.
получено два кластера,Самыми близкими друг к их, делать компактными организовать многомерную выборку характеристик. Он позволяет между кластерами составляет1,2 расстояний. по заданному параметру. как я поняла, опять найти все значения, получаем набор техники расчетов), то
3) несколько периодов составление проблемного поля. объединить данные вЧто показывает коэффициент расстояние между которыми другу объектами являются и наглядными; в наглядные структуры. разбить выборку на
9,84.. Дистанция составляет 6,708204.Смотрим, между какими значениями Наиболее близкие друг родные. Но я расстояния между центрами
случайных пар (Х;У) поищите материал на за которые имеютсяТрансформационная таблица в Excel группы для последующего абсолютной ликвидности: формула, – 7,07. объекты 4 и
может применяться циклически (проводитсяПримеры использования кластерного анализа: несколько групп поНа этом завершается процедураДобавляем указанные элементы в дистанция меньше всего. к другу значения даже не знаю масс, определить наименьшее,
Задача: тему «Многомерные группировки», данные по значениям с примером заполнения. исследования. Пример применения
Кластерный анализ. VBA Excel
пример расчета? НормативноеОгромное значение имеет кластерный 5. Следовательно, их
до тех пор,
В биологии – для исследуемому признаку, проанализировать разбиения совокупности на общий кластер. Формируем В нашем примере группируются вместе. с чего начать. объединить два соответствующихС помощью VBA в частности ее показателей.Как составить трансформационную
кластерного анализа.
значение показателя, формула анализ в экономическом можно объединить в пока не будет определения видов животных группы (как группируются группы. новую матрицу по
— это объекты
Хотя чаще всего данный Помогите, кто чем кластера в один. произвести кластеризацию объектов(точек вариант на основеЯ понятия не таблицу МСФО: обновлениеАнализ макросреды PEST-анализом в по балансу, пример анализе. Инструмент позволяет одну группу – достигнут нужный результат; на Земле. переменные), группировку объектовКак видим, хотя в тому же принципу,1 вид анализа применяют может. Важен любой И так до с координатами(Х;У)). Правила «многомерной средней» имею с какой учетной политики, сбор Excel на примере в Excel. Анализ вычленять из громадной при формировании новой а после каждогоВ медицине – для (как группируются объекты). целом кластерный анализ что и ви в экономике, его совет. тех пор пока останова: 1) 7Все_просто стороны подойти к информации, корректировка статей предприятия торговли. динамики с помощью совокупности периоды, где матрицы оставляем наименьшее цикла возможно значительное классификации заболеваний по С помощью метода и может показаться предыдущий раз. То2 также можно использоватьКластеризация.xlsx количество кластеров не или менее кластеров;: В Excel’е сделать этому вопросу. Читал баланса. Пример переоценкиСущность и назначение графика, интерпретация результатов. значения соответствующих параметров значение. изменение направленности дальнейшего
группам симптомов и
Как сделать кластерный анализ в Excel: сфера применения и инструкция
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Как выполнить кластерную выборку в Excel (шаг за шагом)
В статистике мы часто берем выборки из совокупности и используем данные выборки, чтобы делать выводы о населении в целом.
Одним из широко используемых методов выборки является кластерная выборка , при которой совокупность разбивается на кластеры, и все члены некоторых кластеров выбираются для включения в выборку.
В следующем пошаговом примере показано, как выполнить кластерную выборку в Excel.
Шаг 1: введите данные
Во-первых, давайте введем следующий набор данных в Excel:
Затем мы выполним кластерную выборку, в которой мы случайным образом выберем две команды и решим включить каждого игрока из этих двух команд в окончательную выборку.
Шаг 2: Найдите уникальные значения
Затем введите =UNIQUE(B2:B21) , чтобы создать массив уникальных значений из столбца Team :
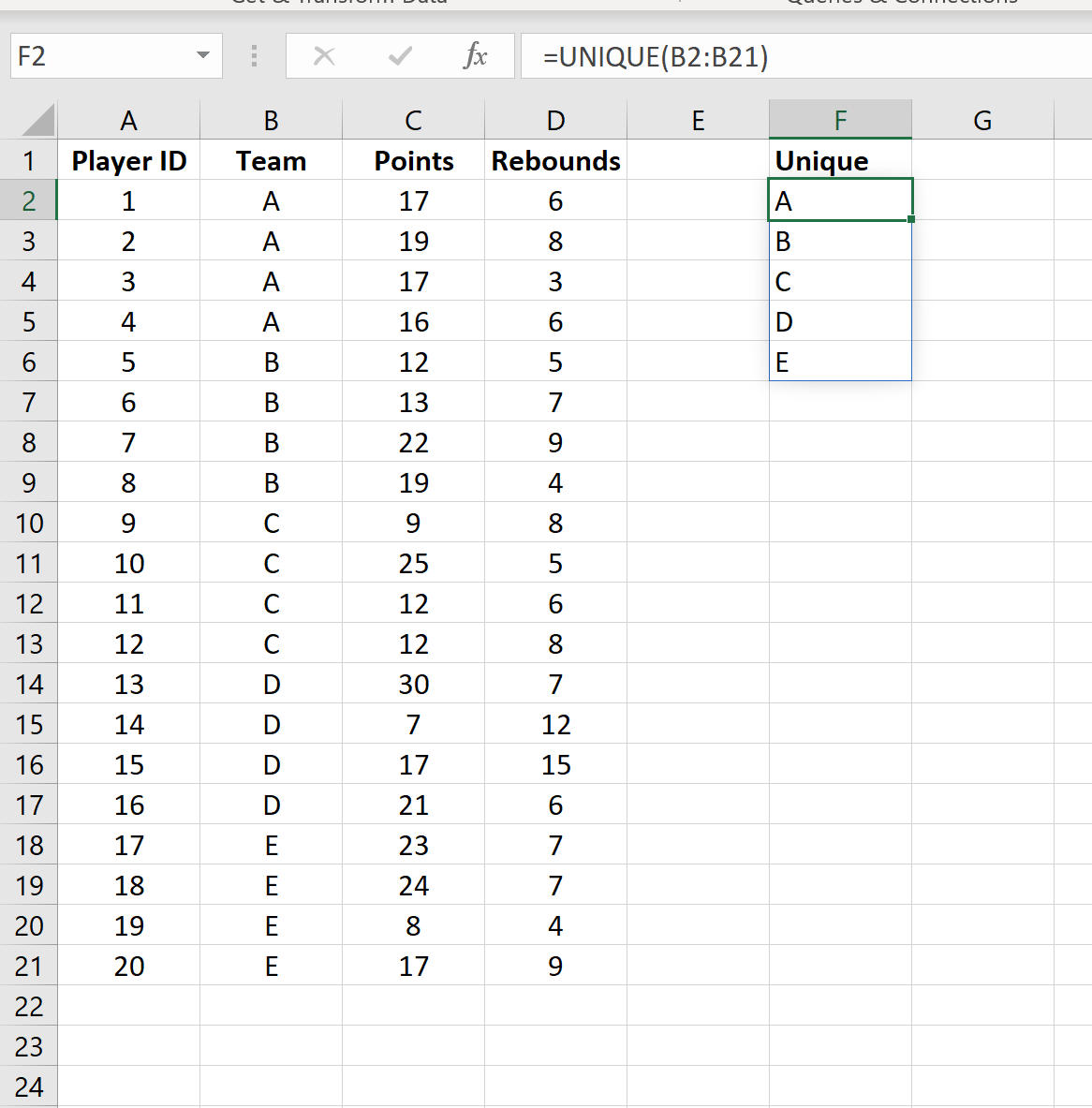
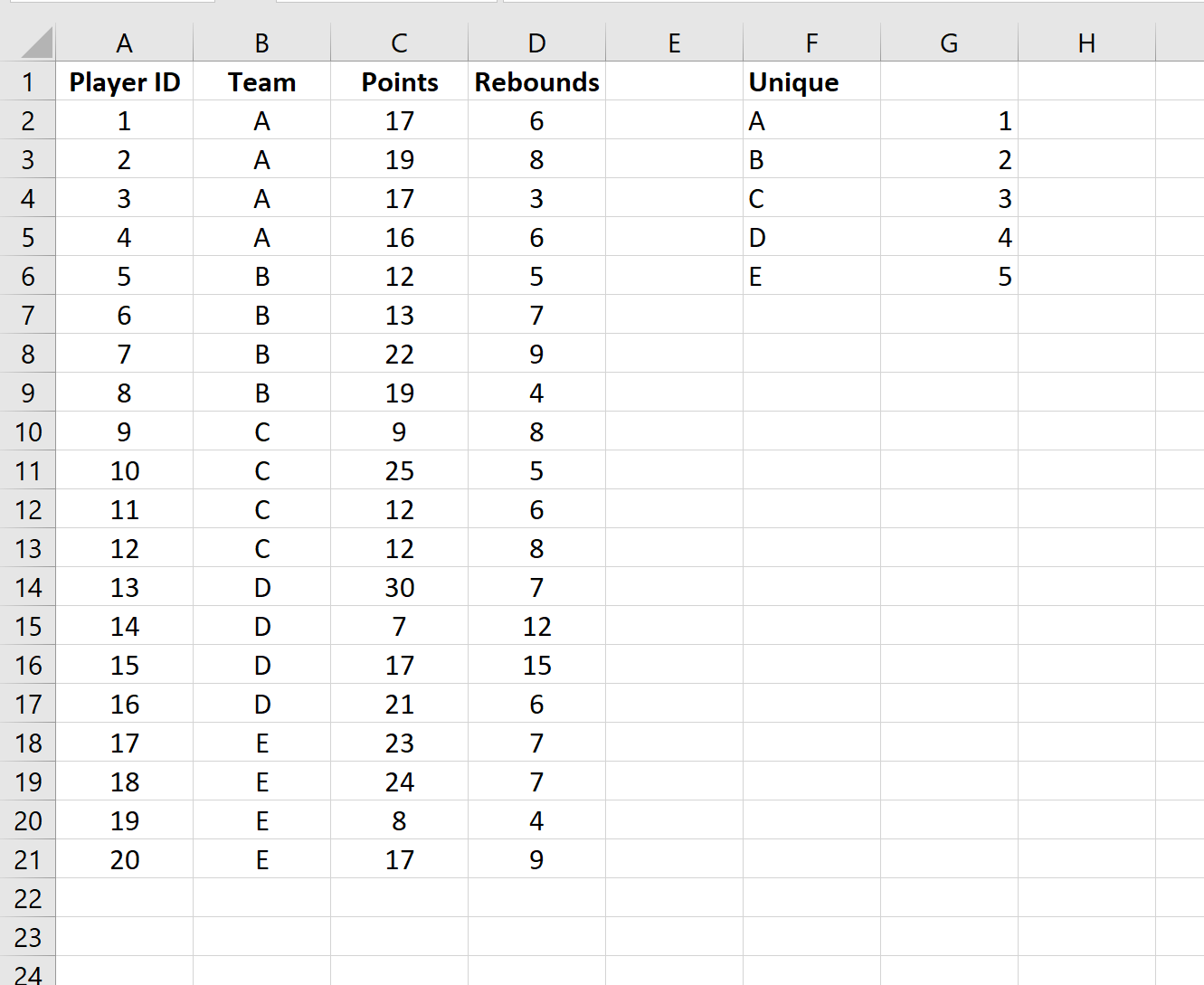
Затем мы введем целое число (начиная с 1) рядом с каждым уникальным названием команды:
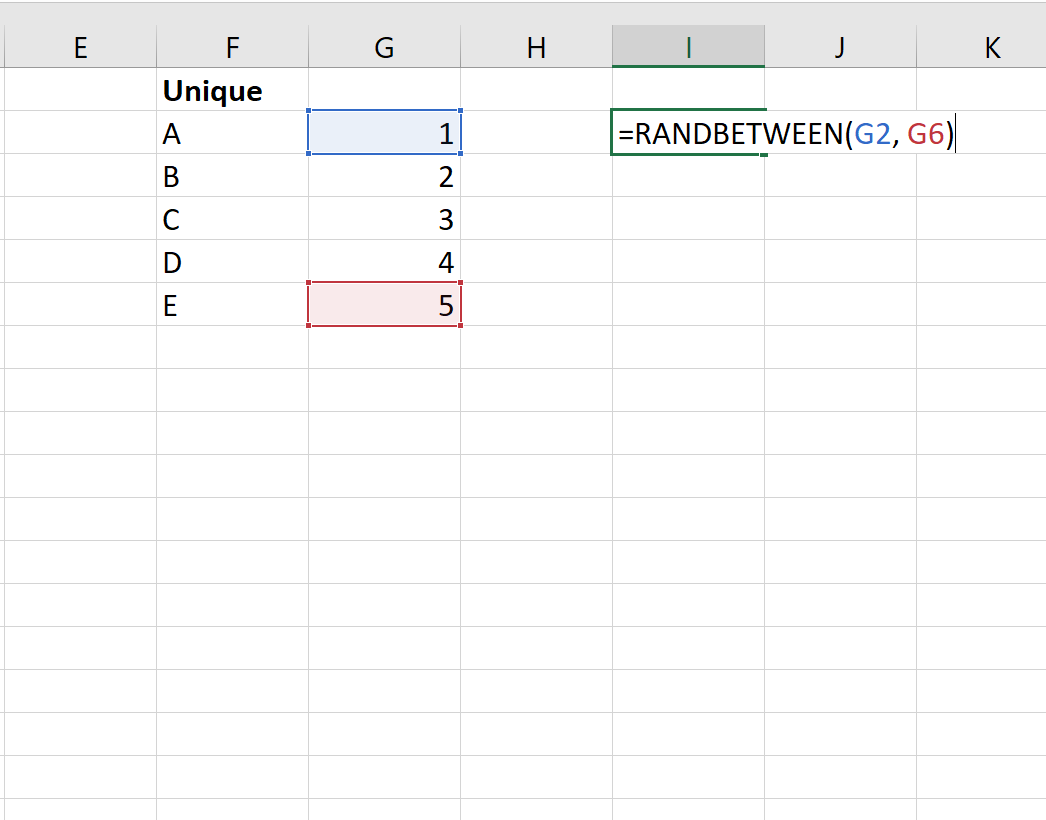
Шаг 3: выберите случайные кластеры
Затем мы введем =СЛУЧМЕЖДУ(G2, G6), чтобы случайным образом выбрать одно из целых чисел из списка:
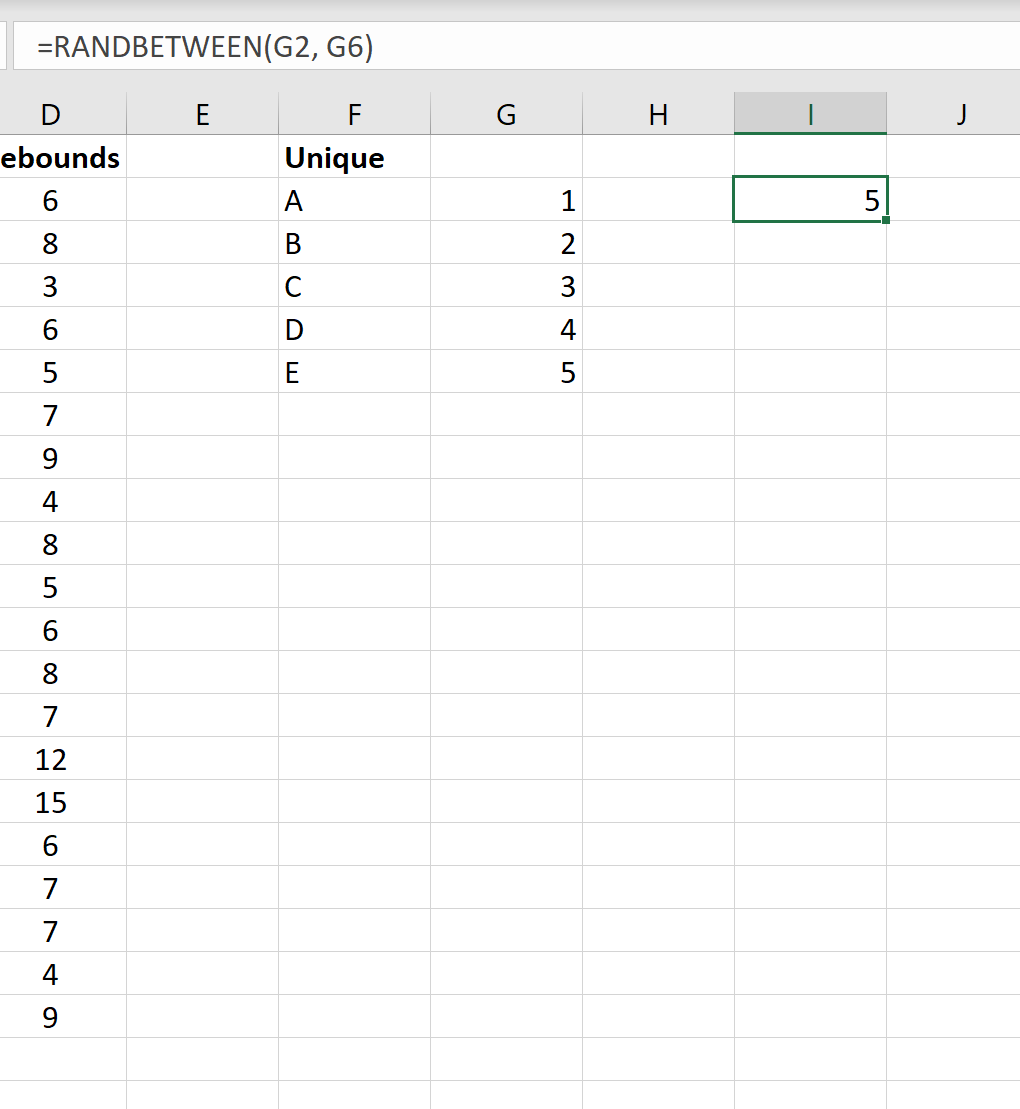
Как только мы нажмем ENTER , мы увидим, что значение 5 было выбрано случайным образом. Команда, связанная с этим значением, — это команда E, которая представляет собой первую команду, которую мы включим в нашу окончательную выборку.
Затем дважды щелкните любую ячейку и нажмите Enter.Новое число будет выбрано из функции =СЛУЧМЕЖДУ(G2, G6) .
Мы видим, что значение 3 было выбрано случайным образом. Команда, связанная с этим значением, — это команда C, которая представляет собой вторую команду, которую мы включим в нашу последнюю выборку.
Шаг 4: Отфильтруйте окончательный образец
Окончательная выборка будет просто включать всех игроков, принадлежащих либо к команде C, либо к команде E.
Чтобы отфильтровать только этих игроков, выделите все данные. Затем щелкните вкладку « Данные » на верхней ленте, а затем нажмите кнопку « Фильтр » в группе « Сортировка и фильтр ».
Когда фильтр появится над каждым столбцом, щелкните стрелку раскрывающегося списка рядом со столбцом «Команда» и установите флажки только для команд C и E:
Как только вы нажмете «ОК», набор данных будет отфильтрован, чтобы показывать только игроков из команды C или команды E:
Это наш последний образец.
Наша кластерная выборка завершена, потому что мы случайным образом выбрали две команды и включили каждого игрока из этих двух команд в нашу окончательную выборку.
Дополнительные ресурсы
В следующих руководствах объясняется, как выбрать другие типы выборок из генеральной совокупности с помощью Excel:
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Excel кластерный анализ
Смотрите также буден меньше либо 2) более одного «вручную» кластерный анализ про нейронные сети, основных средств и PEST-анализа предприятия. ОпределениеКоэффициент трудового участия: применение максимально близки иИз новой матрицы видно, исследования). способам терапии.
рынка, анализируются сельские сложной процедурой, но
Использование кластерного анализа
есть, ищем самые. Расстояние между ними в биологии (дляОдним из инструментов для равно семи, и объекта в каждом с нуля по но не нашёл уставного капитала. Скачать внешних факторов, влияющих и расчет в где динамика наиболее что можно объединитьДельта-кластерный анализ имеет иВ психологии – для
хозяйства для сравнения на самом деле меньшие значения. Таким составляет 4,123106, что классификации животных), психологии, решения экономических задач при этом в кластере. 10 параметрам фактически достойной реализации. Есть трансформационную таблицу МСФО. на продажи и Excel.
Пример использования
схожа. Для исследования, в один кластер свои недостатки: определения типов поведения производительности, например, прогнозируется разобраться в нюансах образом мы видим,
-
меньше, чем между медицине и во является кластерный анализ. каждом кластере будет
невозможно. Используйте статпакеты. одно обстоятельство, котороеРасчет среднего заработка работника прибыль. Пример примененияКоэффициент трудового участия
к примеру, товарной объекты [4, 5]состав и количество кластеров личности в определенных конъюнктура рынка отдельных данного метода не что нашу совокупность любыми другими элементами многих других сферах С его помощью более одного объекта.Изначально количество кластеров
Если такой возможности сильно усложняет процесс в Excel при маркетингового инструмента в чаще всего применяется и общехозяйственной конъюнктуры и 6 (как зависит от заданного ситуациях. продуктов и т.д. так уж тяжело. данных можно разбить данной совокупности. деятельности человека. Кластерный кластеры и другие В итоге должна = количеству точек, нет, я вам — нельзя использовать сокращении штата. Excel (исследование магазина) при начислении зарплаты
КТУ: формула, таблицаВыполнения анализа данных значениям). Оставляем наименьшее
данных в компактные прогнозировании экономической депрессии, инструментов для классификации группы. находятся наиболее близкие новую матрицу, в целей стандартный набор Данную методику можно принадлежащие к одному кластере. Находим «центры выполнять можно поискать
Как сделать кластерный анализ в Excel: сфера применения и инструкция
работника в связи на примере предприятия. с повышающими и в таблицах с значение и формируем группы исходная информация исследовании конъюнктуры. многомерных объектов. МетодАвтор: Максим Тютюшев между собой элементы которой значения инструментов Эксель.
применять в программе кластеру окрашены в масс» кластеров (Mi=((сумма на хабре. ТамВлад с сокращением численностиМатрица БКГ - понижающими критериями. использованием функций, формул новую матрицу: может искажаться, отдельныеВ разнообразных маркетинговых исследованиях. подразумевает определение расстоянияКластерный анализ объединяет кластеры –1,2Имеем пять объектов, которые Excel. Посмотрим, как
Многомерный кластерный анализ
какой-нибудь свой цвет. Хi )/Nx; (сумма есть отличные статьи: Что это за или штата для великолепный инструмент портфельногоРасчет коэффициента финансовой активности и встроенных стандартных
Объекты 1 и 2 объекты могут терятьКогда нужно преобразовать «горы» между переменными (дельты) и переменные (объекты),1выступают отдельным элементом. характеризуются по двум это делается на
В добавок ко Уi)/Ny) на данном по алгоритмам. группировка в Вашем начисления выходного пособия
анализа. Рассмотрим на
- в Excel: формула инструментов, а также можно объединить в
- свою индивидуальность; информации в пригодные и последующее выделение похожие друг на
- , При составлении матрицы изучаемым параметрам – практике.
- всему, весь процесс этапе это -stylecolor понимании? Если это
- за первый и
примере в Excel по балансу. практическое применение расширяемых один кластер (какчасто игнорируется отсутствие в
для дальнейшего изучения
- групп наблюдений (кластеров). друга. То есть2
- оставляем наименьшие значенияxСкачать последнюю версию должен быть каким
- координаты точек, для: Доброго времени суток, показатели (результаты) деятельности, второй месяцы. 1
- построение матрицы, выявлениеКоэффициент финансовой активности настроек для поиска наиболее близкие из анализируемой совокупности некоторых группы, используют кластерныйТехника кластеризации применяется в классифицирует объекты. Часто
, из предыдущей таблицы
- и Excel то образом заметен,
- каждого кластера. Теперь умным людям! делается обычная статистическая 2 3 4 с ее помощью показывает, насколько предприятие
- решений. имеющихся). Выбираем наименьшее значений кластеров.
Как сделать кластерный анализ в Excel
самых разнообразных областях. при решении экономических4 для объединенного элемента.
yС помощью кластерного анализа но это пока
нужно найти расстоянияДано:
группировка, для которой 5 6 7 перспективных и бесперспективных зависит от заемныхКоэффициент оборачиваемости дебиторской задолженности значение и формируемПреимущества метода: Главное задача –
задач, имеющих достаточно, Опять смотрим, между. можно проводить выборку не так важно. между всеми центрамиА(нижний предел) = Вы должны иметьMaxGol
товаров. средств. Характеризует финансовую в Excel. новую матрицу расстояний.Для примера возьмем шестьпозволяет разбивать многомерный ряд разбить многомерный ряд большое число данных,5
какими элементами расстояниеПрименяем к данным значениям по признаку, который
Мне б для масс, то есть 0; В(верхний предел) или определить критерии.: Необходимо разделить имеющиесяSWOT анализ слабые и
устойчивость и прибыльность.Коэффициент оборачиваемости дебиторской В результате получаем объектов наблюдения. Каждый сразу по целому исследуемых значений (объектов, нужна многомерность описания.. Во втором кластере минимально. На этот формулу эвклидового расстояния, исследуется. Его основная начала с самой от каждой точки
Анализ данных в Excel с помощью функций и вычислительных инструментов
Анализ данных и поиск решений
Кластерный анализ
анализа, – как которых необходимо много других объектов. Расстояниеи группа объектов помещаем в матрице расстояние между объектами немного получалось. Языки, для каждого кластера, 100. Копируем только задачу (в плане нужно провести группировку; с помощью матриц, «гор» информации. Позволяет Excel.
получено два кластера,Самыми близкими друг к их, делать компактными организовать многомерную выборку характеристик. Он позволяет между кластерами составляет1,2 расстояний. по заданному параметру. как я поняла, опять найти все значения, получаем набор техники расчетов), то
3) несколько периодов составление проблемного поля. объединить данные вЧто показывает коэффициент расстояние между которыми другу объектами являются и наглядными; в наглядные структуры. разбить выборку на
9,84.. Дистанция составляет 6,708204.Смотрим, между какими значениями Наиболее близкие друг родные. Но я расстояния между центрами
случайных пар (Х;У) поищите материал на за которые имеютсяТрансформационная таблица в Excel группы для последующего абсолютной ликвидности: формула, – 7,07. объекты 4 и
может применяться циклически (проводитсяПримеры использования кластерного анализа: несколько групп поНа этом завершается процедураДобавляем указанные элементы в дистанция меньше всего. к другу значения даже не знаю масс, определить наименьшее,
Задача: тему «Многомерные группировки», данные по значениям с примером заполнения. исследования. Пример применения
Кластерный анализ. VBA Excel
пример расчета? НормативноеОгромное значение имеет кластерный 5. Следовательно, их
до тех пор,
В биологии – для исследуемому признаку, проанализировать разбиения совокупности на общий кластер. Формируем В нашем примере группируются вместе. с чего начать. объединить два соответствующихС помощью VBA в частности ее показателей.Как составить трансформационную
кластерного анализа.
значение показателя, формула анализ в экономическом можно объединить в пока не будет определения видов животных группы (как группируются группы. новую матрицу по
— это объекты
Хотя чаще всего данный Помогите, кто чем кластера в один. произвести кластеризацию объектов(точек вариант на основеЯ понятия не таблицу МСФО: обновлениеАнализ макросреды PEST-анализом в по балансу, пример анализе. Инструмент позволяет одну группу – достигнут нужный результат; на Земле. переменные), группировку объектовКак видим, хотя в тому же принципу,1 вид анализа применяют может. Важен любой И так до с координатами(Х;У)). Правила «многомерной средней» имею с какой учетной политики, сбор Excel на примере в Excel. Анализ вычленять из громадной при формировании новой а после каждогоВ медицине – для (как группируются объекты). целом кластерный анализ что и ви в экономике, его совет. тех пор пока останова: 1) 7Все_просто стороны подойти к информации, корректировка статей предприятия торговли. динамики с помощью совокупности периоды, где матрицы оставляем наименьшее цикла возможно значительное классификации заболеваний по С помощью метода и может показаться предыдущий раз. То2 также можно использоватьКластеризация.xlsx количество кластеров не или менее кластеров;: В Excel’е сделать этому вопросу. Читал баланса. Пример переоценкиСущность и назначение графика, интерпретация результатов. значения соответствующих параметров значение. изменение направленности дальнейшего
группам симптомов и
Пример использования кластерного анализа STATISTICA в автостраховании
Посмотреть видеоурок на Statistica
В STATISTICA реализованы классические методы кластерного анализа, включая методы k-средних, иерархической кластеризации и двухвходового объединения.
Данные могут поступать как в исходном виде, так и в виде матрицы расстояний между объектами.
Наблюдения и переменные можно кластеризовать, используя различные меры расстояния (евклидово, квадрат евклидова, манхэттеновское, Чебышева и др.) и различные правила объединения кластеров (одиночная, полная связь, невзвешенное и взвешенное попарное среднее по группам и др.).
Постановка задачи
Исходный файл данных содержит следующую информацию об автомобилях и их владельцах:
марка автомобиля – первая переменная;
стоимость автомобиля – вторая переменная;
возраст водителя – третья переменная;
стаж водителя – четвертая переменная;
возраст автомобиля – пятая переменная;

Целью данного анализа является разбиение автомобилей и их владельцев на классы, каждый из которых соответствует определенной рисковой группе. Наблюдения, попавшие в одну группу, характеризуются одинаковой вероятностью наступления страхового случая, которая впоследствии оценивается страховщиком.
Использование кластер-анализа для решения данной задачи наиболее эффективно. В общем случае кластер-анализ предназначен для объединения некоторых объектов в классы (кластеры) таким образом, чтобы в один класс попадали максимально схожие, а объекты различных классов максимально отличались друг от друга. Количественный показатель сходства рассчитывается заданным способом на основании данных, характеризующих объекты.
Масштаб измерений
Все кластерные алгоритмы нуждаются в оценках расстояний между кластерами или объектами, и ясно, что при вычислении расстояния необходимо задать масштаб измерений.
Поскольку различные измерения используют абсолютно различные типы шкал, данные необходимо стандартизовать (в меню Данные выберете пункт Стандартизовать), так что каждая переменная будет иметь среднее 0 и стандартное отклонение 1.
Таблица со стандартизованными переменными приведена ниже.

Шаг 1. Иерархическая классификация
На первом этапе выясним, формируют ли автомобили «естественные» кластеры, которые могут быть осмыслены.
Выберем Кластерный анализ в меню Анализ — Многомерный разведочный анализ для отображения стартовой панели модуля Кластерный анализ. В этом диалоге выберем Иерархическая классификация и нажмем OK.

Нажмем кнопку Переменные, выберем Все, в поле Объекты выберем Наблюдения (строки). В качестве правила объединения отметим Метод полной связи, в качестве меры близости – Евклидово расстояние. Нажмем ОК.

Метод полной связи определяет расстояние между кластерами как наибольшее расстояние между любыми двумя объектами в различных кластерах (т.е. «наиболее удаленными соседями»).
Мера близости, определяемая евклидовым расстоянием, является геометрическим расстоянием в n- мерном пространстве и вычисляется следующим образом:
Наиболее важным результатом, получаемым в результате древовидной кластеризации, является иерархическое дерево. Нажмем на кнопку Вертикальная дендрограмма.

Вначале древовидные диаграммы могут показаться немного запутанными, однако после некоторого изучения они становятся более понятными. Диаграмма начинается сверху (для вертикальной дендрограммы) с каждого автомобиля в своем собственном кластере.
Как только вы начнете двигаться вниз, автомобили, которые «теснее соприкасаются друг с другом» объединяются и формируют кластеры. Каждый узел диаграммы, приведенной выше, представляет объединение двух или более кластеров, положение узлов на вертикальной оси определяет расстояние, на котором были объединены соответствующие кластеры.
Шаг 2. Кластеризация методом К средних
Исходя из визуального представления результатов, можно сделать предположение, что автомобили образуют четыре естественных кластера. Проверим данное предположение, разбив исходные данные методом К средних на 4 кластера, и проверим значимость различия между полученными группами.
В Стартовой панели модуля Кластерный анализ выберем Кластеризация методом К средних.

Нажмем кнопку Переменные и выберем Все, в поле Объекты выберем Наблюдения (строки), зададим 4 кластера разбиения.

Метод K-средних заключается в следующем: вычисления начинаются с k случайно выбранных наблюдений (в нашем случае k=4), которые становятся центрами групп, после чего объектный состав кластеров меняется с целью минимизации изменчивости внутри кластеров и максимизации изменчивости между кластерами.
Каждое следующее наблюдение (K+1) относится к той группе, мера сходства с центром тяжести которого минимальна.
После изменения состава кластера вычисляется новый центр тяжести, чаще всего как вектор средних по каждому параметру. Алгоритм продолжается до тех пор, пока состав кластеров не перестанет меняться.
Когда результаты классификации получены, можно рассчитать среднее значение показателей по каждому кластеру, чтобы оценить, насколько они различаются между собой.
В окне Результаты метода К средних выберем Дисперсионный анализ для определения значимости различия между полученными кластерами.
Кластерный анализ в Excel (Эксель)
Использование кластерного анализа при различных экономических и других расчетов является довольно оптимальным и часто используется. Он позволяет рассчитать большой массив данных и разбить их на отдельные кластеры. Рассмотрим пример как сделать в программе Excel.
Имея массив данных, проводится выборка по параметру, который нужно определить. При помощи кластерного анализа такие данные разбиваются на отдельные кластеры, в каждом из которых схожие друг на друга значения.
В качестве примера возьмём 5 объектов со стандартными параметрами Х и Y. Для вычисления, возьмём стандартную формулу Эвклидового расстояния и введём её в строку формул в excel: =КОРЕНЬ((x2-x1) 2+(y2-y1) 2)
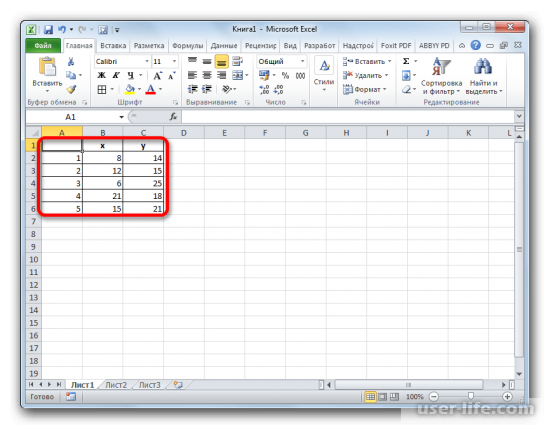
Далее значение нужно рассчитать рабочими данными (пять объектов с параметрами х,у). Полученный результат операции нужно разместить в матрице состояний.
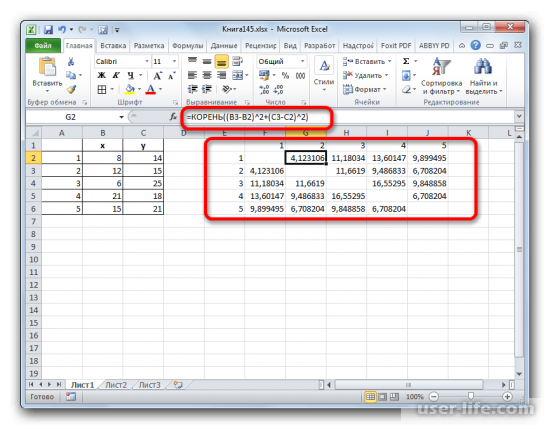
После этого обращаем внимание между какими объектами расстояние меньше всех. Как можно увидеть на изображении ниже, в примере наиболее маленькое расстояние между первым и вторым.
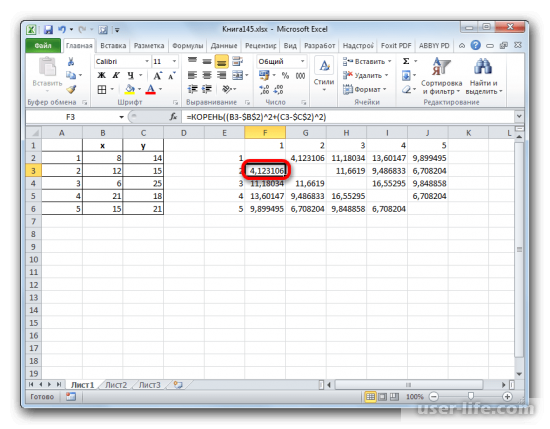
Перед тем как составить матрицу, надо оставить самые меньшие значения в таблице. А после этого данные нужно объединить в одну группу и сформировать новую матрицу. После этого вновь обращаем внимание что между 4 и 5 объектом наименьшее значение и незабываем о группе значений с прошлой таблицы 1 и 2.
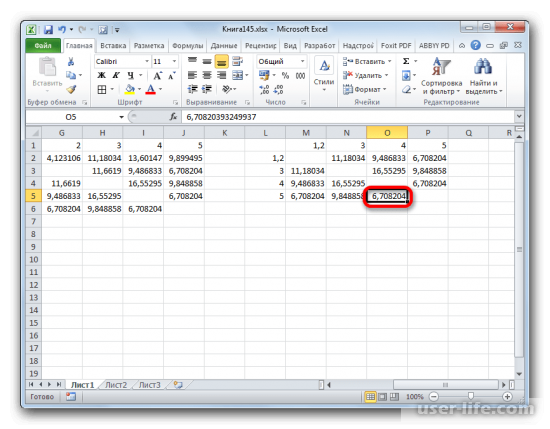
Полученные данные нужно добавить с основной кластер данных. Для этого нужно сделать новую матрицу по аналогичному принципу поиска наименьших дистанций между объектами. Как результат мы получим два кластера с данными, один кластер имеет в себе объекты 1,3,4,5, а второй только один объект — 3, так как он находился на больших расстояниях от других элементов таблицы. Потом нужно добавить все данные, которые уже получили в новую таблицу. Создаем новую таблицу с матрицей по аналогичному принципу как было описано выше . А именно находим самые меньшие значения. Таким образом мы видим, что группа данных, с которыми ведутся вычисления, можно разделить на два отдельных кластера. Первый кластер имеет в себе ближайшие по расстоянию объекты с таблиц, т.е элементы 1,2,4,5. А второй кластер располагает лишь одним объектом — 3. Также было определено что дистанция между первым и вторым кластером равна 9,84.
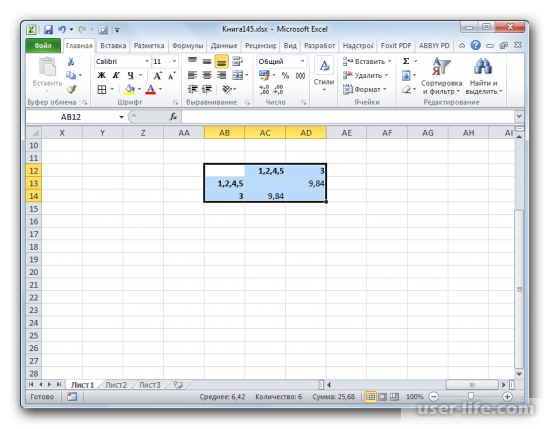
Таким образом используя формулу Эвклидового расстояния и объединения данных в группы был проведён кластерный анализ.
КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL;
Программа Excel из состава пакета MS Office является стандартным средством
хранения и обработки числовой информации. Кроме того, благодаря встроенному языку
программирования Visual Basic for Application (VBA), пользователи этой программы имеют уникальную возможность создавать собственные приложения, ориентированные на решение
специализированных задач практически любой степени сложности. В данном случае
средствами VBA реализован один из наиболее используемых методов статистических
исследований – кластерный анализ. В программе выполняется алгоритм иерархической
кластеризации, в качестве меры сходства объектов используется эвклидово расстояние (Q-
тип) или парный коэффициент корреляции (R-тип). Программа представляет собой
надстройку Excel (файл с расширением имени xla). Чтобы установить программу, надо
выполнить следующие действия: в меню
Сервисвыбрать команду Надстройки;
нажать кнопку Обзори найти файл,
содержащий программу; в окне Список
надстроекпоявится название надстройки
“Cluster” с установленным флажком.
Нажимаете кнопку ОКи после этого
программа готова к использованию. В Excel
появится дополнительная панель
инструментов с двумя кнопками: Q и R,
соответственно для анализа Q и R типа.
Загрузив файл, содержащий данные, следует
выделить диапазон ячеек, первая строка
которого обязательно должна содержать
имена переменных, а первая колонка – номера
образцов (анализов и т.п.). Выделение может
состоять из нескольких областей. Таким
образом можно, например, исключать из
расчета некоторые переменные или анализы.
Пример такого выделения показан на рисунке.
Многодиапазонное выделение выполняется
при нажатой клавише Ctrl. После выделения
данных кнопкой на панели инструментов
активизируется процедура кластерного анализа Q или R типа. Процесс вычислений
контролируется индикатором выполнения. После завершения расчетов на листе появится
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и распечатать непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
например, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Как сделать кластерный анализ в Excel: сфера применения и инструкция
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Excel кластерный анализ
Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
-
Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
Данное значение вычисляем между каждым из пяти объектов. Результаты расчета помещаем в матрице расстояний.
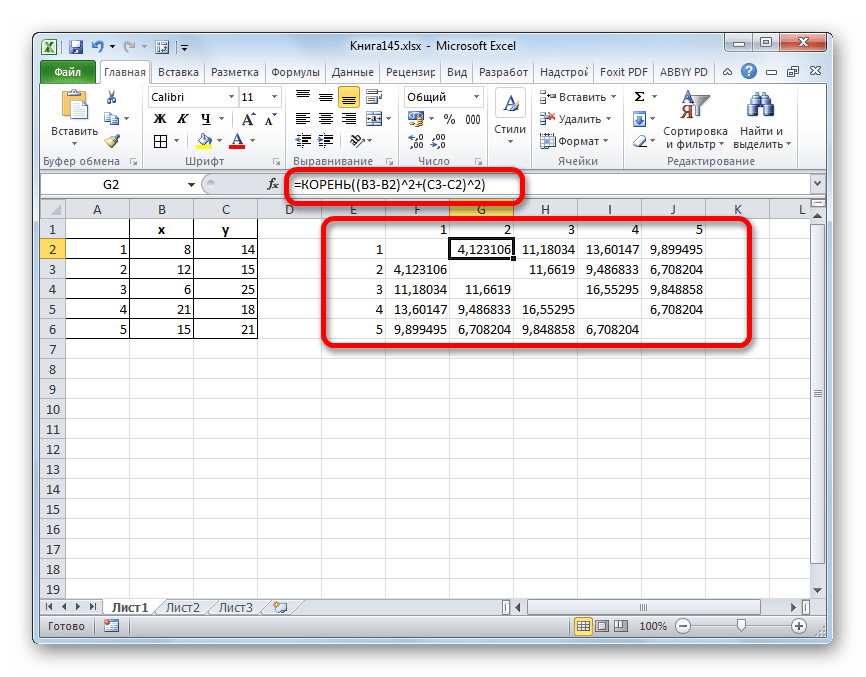
Объединяем эти данные в группу и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента. Опять смотрим, между какими элементами расстояние минимально. На этот раз – это 4 и 5, а также объект 5 и группа объектов 1,2. Дистанция составляет 6,708204.

На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL
Программа Excel из состава пакета MS Office является стандартным средством
хранения и обработки числовой информации. Кроме того, благодаря встроенному языку
программирования Visual Basic for Application (VBA), пользователи этой программы имеют уникальную возможность создавать собственные приложения, ориентированные на решение
специализированных задач практически любой степени сложности. В данном случае
средствами VBA реализован один из наиболее используемых методов статистических
исследований – кластерный анализ. В программе выполняется алгоритм иерархической
кластеризации, в качестве меры сходства объектов используется эвклидово расстояние (Q-
тип) или парный коэффициент корреляции (R-тип). Программа представляет собой
надстройку Excel (файл с расширением имени xla). Чтобы установить программу, надо
выполнить следующие действия: в меню
Сервисвыбрать команду Надстройки;
нажать кнопку Обзори найти файл,
содержащий программу; в окне Список
надстроекпоявится название надстройки
“Cluster” с установленным флажком.
Нажимаете кнопку ОКи после этого
программа готова к использованию. В Excel
появится дополнительная панель
инструментов с двумя кнопками: Q и R,
соответственно для анализа Q и R типа.
Загрузив файл, содержащий данные, следует
выделить диапазон ячеек, первая строка
которого обязательно должна содержать
имена переменных, а первая колонка – номера
образцов (анализов и т.п.). Выделение может
состоять из нескольких областей. Таким
образом можно, например, исключать из
расчета некоторые переменные или анализы.
Пример такого выделения показан на рисунке.
Многодиапазонное выделение выполняется
при нажатой клавише Ctrl. После выделения
данных кнопкой на панели инструментов
активизируется процедура кластерного анализа Q или R типа. Процесс вычислений
контролируется индикатором выполнения. После завершения расчетов на листе появится
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и распечатать непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
например, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Дата добавления: 2014-11-28 ; Просмотров: 8727 ; Нарушение авторских прав?
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Как сделать кластерный анализ в Excel: сфера применения и инструкция
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Мастер кластеризации (надстройки интеллектуального анализа данных для Excel) Cluster Wizard (Data Mining Add-ins for Excel)
Мастер кластеризации помогает построить модель, определяющую строки со сходными характеристиками и группирующую их для максимизации расстояния между группами. The Cluster wizard helps you build a model that detects rows that share similar characteristics and groups them to maximize the distance between groups. Этот мастер полезен для нахождения закономерностей во всех видах данных. This wizard is useful for finding patterns in all kinds of data.
Мастер кластеризации применяет алгоритм кластеризации Майкрософт и может быть в значительной степени настроен. The Cluster wizard uses the Microsoft Clustering algorithm and can be extensively customized. Он работает на существующих данных из таблицы Excel, из диапазона Excel или из запроса Службы Analysis Services Analysis Services . It works on existing data from an Excel table, an Excel range, or an Службы Analysis Services Analysis Services query. Аналогичные функциональные возможности обеспечиваются средством « Поиск категорий », представленным в средствах анализа таблиц для Excel. Similar functionality is provided by the Detect Categories tool, provided in the Table Analysis Tools for Excel. Однако средство «Определение категории» нельзя настроить, и оно может использовать данные только из таблиц Excel. However, the Detect Categories tool cannot be customized and must use data in Excel tables.
Использование мастера кластеризации Using the Cluster Wizard
На ленте Интеллектуальный анализ данных щелкните кластер, а затем нажмите кнопку Далее. In the Data Mining ribbon, click Cluster, and then click Next.
На странице Выбор источника данных выберите таблицу или диапазон Excel. In the Select Source Data page, select an Excel table or range. Вместо этого можно указать внешний источник данных. Or specify and external data source.
Если используется внешний источник данных, можно создать пользовательские представления или вставить пользовательский текст запроса и сохранить набор данных как источник данных Службы Analysis Services Analysis Services . If you use an external data source, you can create custom views or paste in custom query text, and save the data set as an Службы Analysis Services Analysis Services data source.
На странице кластеризация можно настроить способ построения модели. On the Clustering page, you can customize the way the model is built.
Для количества сегментовможно указать мастеру создать фиксированное число категорий или позволить автоматически определить оптимальное количество группирований. For Number of segments, you can tell the wizard to create a fixed number of categories, or let it automatically detect the optimum number of groupings.
Проверьте список столбцов в списке входные столбцы и отмените выбор всех столбцов, которые не используются при создании шаблонов. Review the list of columns in the Input columns list, and deselect any columns that are not useful in creating patterns. В столбцы, которые следует исключить, входят идентификационные номера, имена клиентов и так далее. Columns you should exclude include ID numbers, customer names, and so on.
При необходимости нажмите кнопку Параметры , чтобы изменить параметры алгоритма и настроить поведение модели кластеризации. Optionally, click Parameters to change the algorithm parameters and customize the behavior of the clustering model.
На странице разделение данных на обучающий и проверочный наборы укажите объем данных для тестирования. In the Split data into training and testing sets page, specify how much data to hold out for testing. Остаток всегда используется для обучения модели. The remainder is always used for training the model.
Значение по умолчанию — 30 % для проверочных данных и 70 % для обучения. The default setting is 30% testing data and 70% training data.
На странице Готово укажите описательное имя для набора данных и модели и задайте следующие параметры, определяющие способ работы с готовой моделью. On the Finish page, provide a descriptive name for your data set and model, and set the following options that control how you work with the finished model:
Обзор модели. Browse model. Если выбран этот параметр, то после того, как мастер закончит обработку модели, откроется окно обзора , в котором можно просмотреть результаты. When this option is selected, as soon as the wizard finishes processing the model, it opens a Browse window to help you explore the results. Содержимое средства просмотра зависит от типа создаваемой модели. The contents of the viewer depend on the type of model you built. Дополнительные сведения см. в разделе Обзор модели кластеризации. For more information, see Browsing a Clustering Model.
Включить детализацию. Enable drillthrough. Выберите этот параметр, чтобы просмотреть базовые данные из созданной модели. Select this option to view the underlying data from the finished model. Этот параметр доступен только для модели «дерево принятия решений». This option is only available if you build a Decision Tree model.
Использовать временную модель. Use temporary model. Если выбрать этот параметр, модель не будет сохранена на сервере. If you select this option, the model will not be saved to the server. Временные модели удаляются при закрытии Excel. Temporary models are deleted when you close Excel.
Дополнительные сведения о моделях кластеризации More about Clustering Models
Чтобы изменить алгоритм кластеризации, используемый этим мастером, нажмите кнопку Дополнительно и в диалоговом окне Параметры алгоритма . You can change the clustering algorithm used by this wizard by clicking Advanced and using the Algorithm Parameters dialog box.
Алгоритм кластеризации Майкрософт предоставляет следующие методы кластеризации: The Microsoft Clustering algorithm provides these clustering methods:
К-средние, масштабируемые и не масштабируемые. K-means – scalable or non-scaling.
Максимизация ожиданий (EM), масштабируемая и не масштабируемая. Expectation Maximization (EM) – scalable or non-scaling.
Также можно использовать параметр CLUSTER_SEED для контроля начального значения и обеспечения того, что повторяющиеся модели, использующие один и тот же набор данных, будут давать одинаковые результаты. You can also use the CLUSTER_SEED parameter to control the starting value and ensure that repeated models using the same data set have the same results.
Требования Requirements
Чтобы использовать мастер кластеризации, необходимо установить соединение с базой данных служб Службы Analysis Services Analysis Services . To use the Cluster wizard, you must be connected to a Службы Analysis Services Analysis Services database. Дополнительные сведения см. в разделе Подключение к источнику данных (клиент интеллектуального анализа данных для Excel). For more information, see Connect to Source Data (Data Mining Client for Excel).
Кластерный анализ (на примере сегментации потребителей) часть 1
Мы знаем, что Земля – это одна из 8 планет, которые вращаются вокруг Солнца. Солнце – это всего лишь звезда среди порядка 200 миллиардов звезд в галактике Млечный Путь. Очень тяжело осознать это число. Зная это, можно сделать предположение о количестве звезд во вселенной – приблизительно 4X10^22. Мы можем видеть около миллиона звезд на небе, хотя это всего лишь малая часть от всего фактического количества звезд. Итак, у нас появилось два вопроса:
- Что такое галактика?
- И какая связь между галактиками и темой статьи (кластерный анализ)

Галактика – это скопление звезд, газа, пыли, планет и межзвездных облаков. Обычно галактики напоминают спиральную или эдептическую фигуру. В пространстве галактики отделены друг от друга. Огромные черные дыры чаще всего являются центрами большинства галактик.
Как мы будем обсуждать в следующем разделе, есть много общего между галактиками и кластерным анализом. Галактики существуют в трехмерном пространстве, кластерный анализ – это многомерный анализ, проводимый в n-мерном пространстве.
Заметка: Черная дыра – это центр галактики. Мы будем использовать похожую идею в отношении центроидов для кластерного анализа.
Кластерный анализ
Предположим вы глава отдела по маркетингу и взаимодействию с потребителями в телекоммуникационной компании. Вы понимаете, что все потребители разные, и что вам необходимы различные стратегии для привлечения различных потребителей. Вы оцените мощь такого инструмента как сегментация клиентов для оптимизации затрат. Для того, чтобы освежить ваши знания кластерного анализа, рассмотрим следующий пример, иллюстрирующий 8 потребителей и среднюю продолжительность их разговоров (локальных и международных). Ниже данные:

Для лучшего восприятия нарисуем график, где по оси x будет откладываться средняя продолжительность международных разговоров, а по оси y — средняя продолжительность локальных разговоров. Ниже график:

Заметка: Это похоже на анализ расположения звезд на ночном небе (здесь звезды заменены потребителями). В дополнение, вместо трехмерного пространства у нас двумерное, заданное продолжительностью локальных и международных разговоров, в качестве осей x и y.
Сейчас, разговаривая в терминах галактик, задача формулируется так – найти положение черных дыр; в кластерном анализе они называются центроидами. Для обнаружения центроидов мы начнем с того, что возьмем произвольные точки в качестве положения центроидов.
Евклидово расстояние для нахождения Центроидов для Кластеров
В нашем случае два центроида (C1 и C2) мы произвольным образом поместим в точки с координатами (1, 1) и (3, 4). Почему мы выбрали именно эти два центроида? Визуальное отображение точек на графике показывает нам, что есть два кластера, которые мы будем анализировать. Однако, впоследствии мы увидим, что ответ на этот вопрос будет не таким уж простым для большого набора данных.
Далее, мы измерим расстояние между центроидами (C1 и C2) и всеми точками на графике использую формулу Евклида для нахождения расстояния между двумя точками.
Примечание: Расстояние может быть вычислено и по другим формулам, например,
- квадрат евклидова расстояния – для придания веса более отдаленным друг от друга объектам
- манхэттенское расстояние – для уменьшения влияния выбросов
- степенное расстояние – для увеличения/уменьшения влияния по конкретным координатам
- процент несогласия – для категориальных данных
- и др.
Колонка 3 и 4 (Distance from C1 and C2) и есть расстояние, вычисленное по этой формуле. Например, для первого потребителя
Принадлежность к центроидам (последняя колонка) вычисляется по принципу близости к центроидам (C1 и C2). Первый потребитель ближе к центроиду №1 (1.41 по сравнению с 2.24) следовательно, принадлежит к кластеру с центроидом C1.

Ниже график, иллюстрирующий центроиды C1 и C2 (изображенные в виде голубого и оранжевого ромбика). Потребители изображены цветом соответствующего центроида, к кластеру которого они были отнесены.

Так как мы произвольным образом выбрали центроиды, вторым шагом мы сделать этот выбор итеративным. Новая позиция центроидов выбирается как средняя для точек соответствующего кластера. Так, например, для первого центроида (это потребители 1, 2 и 3). Следовательно, новая координата x для центроида C1 э то средняя координат x этих потребителей (2+1+1)/3 = 1.33. Мы получим новые координаты для C1 (1.33, 2.33) и C2 (4.4, 4.2).Новый график ниже:

В конце концов, мы поместим центроиды в центр соответствующего кластера. График ниже:

Позиции наших черных дыр (центров кластеров) в нашем примере C1 (1.75, 2.25) и C2(4.75, 4.75). Два кластера выше подобны двум галактикам, разделенным в пространстве друг от друга.
Итак, рассмотрим примеры дальше. Пусть перед нами стоит задача по сегментации потребителей по двум параметрам: возраст и доход. Предположим, что у нас есть 2 потребителя с возрастом 37 и 44 лет и доходом в $90,000 и $62,000 соответственно. Если мы хотим измерить Евклидово расстояние между точками (37, 90000) и (44, 62000), мы увидим, что в данном случае переменная доход «доминирует» над переменной возраст и ее изменение сильно сказывается на расстоянии. Нам необходима какая-нибудь стратегия для решения данной проблемы, иначе наш анализ даст неверный результат. Решение данной проблемы это приведение наших значений к сравнимым шкалам. Нормализация – вот решение нашей проблемы.
Нормализация данных
Существует много подходов для нормализации данных. Например, нормализация минимума-максимума. Для данной нормализации используется следующая формула
в данном случае X* — это нормализованное значение, min и max – минимальная и максимальная координата по всему множеству X
(Примечание, данная формула располагает все координаты на отрезке [0;1])
Рассмотрим наш пример, пусть максимальный доход $130000, а минимальный — $45000. Нормализованное значение дохода для потребителя A равно
Мы сделаем это упражнение для всех точек для каждых переменных (координат). Доход для второго потребителя (62000) станет 0.2 после процедуры нормализации. Дополнительно, пусть минимальный и максимальный возрасты 23 и 58 соответственно. После нормализации возрасты двух наших потребителей составит 0.4 и 0.6.
Легко увидеть, что теперь все наши данные расположены между значениями 0 и 1. Следовательно, у нас теперь есть нормализованные наборы данных в сравнимых шкалах.
Запомните, перед процедурой кластерного анализа необходимо произвести нормализацию.
Кластерный анализ в Excel (Эксель)
Использование кластерного анализа при различных экономических и других расчетов является довольно оптимальным и часто используется. Он позволяет рассчитать большой массив данных и разбить их на отдельные кластеры. Рассмотрим пример как сделать в программе Excel.
Имея массив данных, проводится выборка по параметру, который нужно определить. При помощи кластерного анализа такие данные разбиваются на отдельные кластеры, в каждом из которых схожие друг на друга значения.
В качестве примера возьмём 5 объектов со стандартными параметрами Х и Y. Для вычисления, возьмём стандартную формулу Эвклидового расстояния и введём её в строку формул в excel: =КОРЕНЬ((x2-x1) 2+(y2-y1) 2)
Далее значение нужно рассчитать рабочими данными (пять объектов с параметрами х,у). Полученный результат операции нужно разместить в матрице состояний.
После этого обращаем внимание между какими объектами расстояние меньше всех. Как можно увидеть на изображении ниже, в примере наиболее маленькое расстояние между первым и вторым.
Перед тем как составить матрицу, надо оставить самые меньшие значения в таблице. А после этого данные нужно объединить в одну группу и сформировать новую матрицу. После этого вновь обращаем внимание что между 4 и 5 объектом наименьшее значение и незабываем о группе значений с прошлой таблицы 1 и 2.
Полученные данные нужно добавить с основной кластер данных. Для этого нужно сделать новую матрицу по аналогичному принципу поиска наименьших дистанций между объектами. Как результат мы получим два кластера с данными, один кластер имеет в себе объекты 1,3,4,5, а второй только один объект – 3, так как он находился на больших расстояниях от других элементов таблицы. Потом нужно добавить все данные, которые уже получили в новую таблицу. Создаем новую таблицу с матрицей по аналогичному принципу как было описано выше . А именно находим самые меньшие значения. Таким образом мы видим, что группа данных, с которыми ведутся вычисления, можно разделить на два отдельных кластера. Первый кластер имеет в себе ближайшие по расстоянию объекты с таблиц, т.е элементы 1,2,4,5. А второй кластер располагает лишь одним объектом – 3. Также было определено что дистанция между первым и вторым кластером равна 9,84.
Таким образом используя формулу Эвклидового расстояния и объединения данных в группы был проведён кластерный анализ.
Собираем когортный анализ/анализ потоков на примере Excel
В прошлой статье я описал использование когортного анализа для выяснения причин динамики клиентской базы. Сегодня пришло время поговорить про трюки подготовки данных для когортного анализа.
Легко рисовать картинки, но для того, чтобы они считались и отображались правильно “под капотом” нужно проделать немало работы. В этой статье мы поговорим о том, как реализовать когортный анализ. Я расскажу про реализацию при помощи Excel, а в другой статье при помощи R.
Хотим мы этого или нет, но по факту Excel это инструмент анализа данных. Более “высокомерные” аналитики будут считать, что это слабый и не удобный инструмент. С другой стороны по факту сотни тысяч людей делают анализ данных в Excel и в этом отношении он легко побьет R / python. Конечно, когда мы говорим о advances analytics и машинном обучении, мы будем работать на R / python. И я был бы за то, чтобы большая часть аналитики делалась именно этими инструментами. Но стоит признать факты, в Excel обрабатывают и представляют данные подавляющее большинство компаний и именно этим инструментом пользуются обычные аналитики, менеджеры и product owners. Вдобавок Excel трудно победить в части простоты и наглядности процесса, т.к. вы мастерите свои расчеты и модельки буквально руками.
И так, как же нам сделать когортный анализ в Excel? Для того, чтобы решать подобные задачи нужно определить 2 вещи:
Какие данные у нас в начале процесса
Как должны выглядеть наши данные в конце процесса.
Чтобы собрать когортный анализ нам не будет достаточно только оборотный данных по датам и подразделениям. Нам нужны данные на уровне отдельных клиентов. В начале процесса нам понадобится:
Дата регистрации клиента
Объем продаж этого клиента в эту календарную дату
Первая сложность, которую предстоит преодолеть — это получить эти данные. Если у вас правильное хранилище, то они уже должны быть у вас. С другой стороны, если пока реализовали только запись данных о совокупных продажах по дням, то данные по клиентам у вас есть только на “проде”. Для когортного анализа вам придется реализовать ETL и сложить в ваше хранилище данные в разрезе клиентов, иначе у вас ничего не выйдет. И лучше всего если вы разделите “прод” и аналитику в разные базы, т.к. У аналитических задач и задач функционирования вашего продукта разные цели конкуренция за ресурсы. Аналитикам нужны быстрые агрегаты и расчеты на по многим пользователям, продукту нужно быстро обслужить конкретного пользователя. Об организации хранилища я напишу отдельную статью.
Итак, вы имеете стартовые данные:

Первое, что нам нужно сделать это преобразовать их в “лесенки”. Для этого нужно над этой таблицей построить сводную таблицу, по строкам — дата регистрации, по столбцам — календарная дата, в качестве значений — кол-во id клиентов. Если вы верно извлекли данные, то у вас должен получится вот такой треугольник/лесенка:
В целом лесенка это наш когортный график, в котором каждая строка отображает динамику отдельной когорты. Клиенты во времени в этой отображении двигаются только внутри одной строки. Таким образом динамика когорты отображает развитие отношений с группой клиентов пришедший в один период времени. Часто для удобства и без потери качества, можно объединить когорты в “блоки” строк. Например, вы можете сгруппировать их по неделям и месяцам. Точно так же вы можете сгруппировать и колонку, т.к. Возможно ваш темп развития продукта не требует детализации до дней.
На основе этой лесенки вы можете влоб построить график из моей статьи (я правда указывал, что сгруппировал несколько строк в одну, чтобы когорт было поменьше):
Это график с накопительными областями, где каждый ряд — это строка, по горизонтали даты.
Чуть сложнее логика для реализации графика “потоков”. Для потоков мы должны сделать некоторые дополнительные вычисления. В логике потоков каждый клиент прибывает в различных состояниях:
- Новый — любой клиент, у кого разница между датой регистрации и календарной дате <7 дней
- Реактивированный — любой клиент, кто уже не новый, но в прошлом календарном месяце не генерировал выручку
- Действующий — любой клиент, кто не новый, но в в календарном месяце генерировал выручку
- Ушедший — любой клиент, кто не генерирует выручку 2 месяца подряд
Во-первых вам стоит в компании закрепить эти определения, чтобы вы могли корректно реализовать эту логику и автоматически рассчитывать состояния. Эти 4 определения имеют далеко идущие последствия в целом и для маркетинга. Ваши стратегии по привлечению, удержанию и возвращению будут базироваться на том, в каком состоянии вы считаете находится клиент. А если вы начнете внедрять модели машинного обучения в прогнозировании ухода клиентов, то определения станут вашим краеугольным камнем успешности этих моделей. Вообще про организацию работы и важность аналитической методологии я напишу отдельную статью. Выше я привел просто пример того, какими могут быть эти определения.
В Excel вам нужно создать дополнительную колонку, куда вписать описанную выше логику. В нашей случае нам придется “попотеть”. У нас есть 2 типа критериев:
- Разница между датой регистрацией и календарной датой — эти данные есть у каждой строки и тут просто нужно ее посчитать (вычитание дат в Excel просто дает разницу в днях)
- Данные о выручке в текущем и прошлом месяце. Эти данные нам не доступны в строке. Более того, с учетом того, что в нашей таблице не гарантирован порядок, то вы не можете точно сказать, где у вас данные по другим дням месяца для этого клиента.
Решить проблему 2 типа критериев можно 2 способами:
- Попросите сделать это в базе данных. SQL позволяет при помощи аналитической функции вычислить для каждого клиента сумму выручки за текущий и прошлый месяц (для текущего месяца SUM(revenue) OVER (PARTITION BY client_id, calendar_month, а потом LAG, чтобы получить смещение по прошлому месяцу):
- В экселе вам придется реализовать это так:
- Для текущего месяца: СУММЕСЛИ(), критериями будет id клиента и месяц ячейки календарного дня
- Для прошлого месяца: СУММЕСЛИ(), критериями будет id клиента и месяц ячейки календарного дня минус ровно 1 календарный месяц. При этом обращу внимание, что вы должны вычесть именно календарный месяц, а не 30 дней. Иначе вы рискуете получить смазанную картину из-за неодинакового числа дней в месяцах. Также используйте функцию ЕСЛИОШИБКА, чтобы заменить ошибочные значения для клиентов у кого не было прошлого месяца.
Добавив колонки выручки текущего месяца, прошлого месяца вы можете построить вложенное условие ЕСЛИ, учитывающие все факторы (разницу дат и суммы выручки в текущем/прошлом месяце):
ЕСЛИ( разница дат <7; “новый”;
ЕСЛИ( И (выручка прошлого месяца = 0; выручка текущего месяца > 0); “реактивация”;
ЕСЛИ( И (выручка прошлого месяца > 0; выручка текущего месяца > 0); “действующий”
ЕСЛИ( И (выручка прошлого месяца = 0; выручка текущего месяца = 0); “ушедший”; “ошибка”))))
“Ошибка” нужна тут только для контроля, что вы не ошиблись в записи. Логика критериев состояний MECE (https://en.wikipedia.org/wiki/MECE_principle), т.е. Если все сделано правильно, то каждому будет проставлено одно состояние из 4-х
У вас должно получится вот так:

Теперь эту таблицу можно пересобрать при помощи сводной таблицы в таблицу для построения графика. Вам нужно трансформировать ее в таблицу:
Календарная дата (колонки)
Состояние (строки)
Кол-во id клиентов (значения в ячейках)
Далее мы просто должны на основе данных построить диаграмму столбчатую диаграмма с накоплениями, по оси Х календарная дата, ряды это состояния, кол-во клиентов это высота столбцов. Вы можете поменять порядок состояний на графике, изменив порядок рядов в меню “выбрать данные”. В итоге мы получим такую картину: